Why is NuGet search in Rider so fast?
I’m the guy who develops the NuGet manager in Rider. It’s not ready yet, there are some bugs here and there, but it already works pretty well. The feature which I am most proud of is smart and fast search:
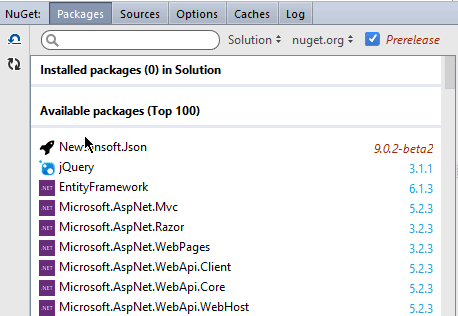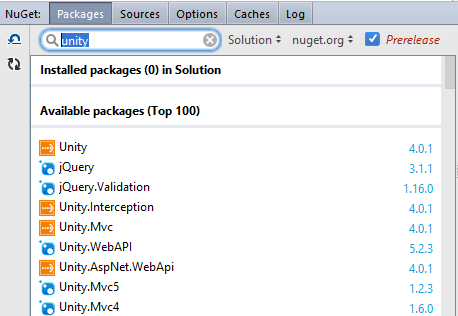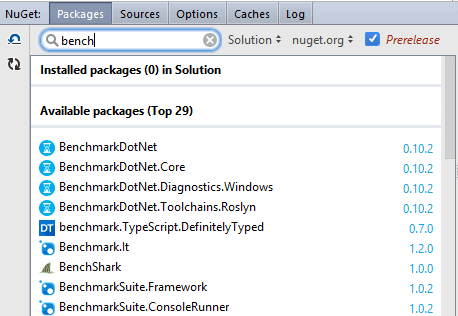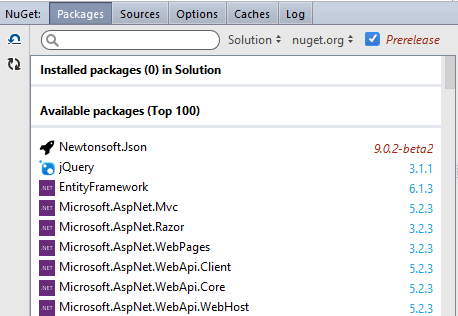
Today I want to share with you some technical details about how it was implemented.
Caching
In Rider, we are using NuGet.Client. It is a package with a set of APIs which allows doing all the basic NuGet operations: install, uninstall, restore, and search. So, we can write something like this
packageSearchResource.SearchAsync(searchTerm, searchFilters, skip, take, logger, cancellationToken);
and get a list of packages. And this method is a bottleneck: searching for ten packages can take about 1 second for a remote feed. If you want to form a big list of search results, you have to wait tens of seconds.
But we don’t want to wait so long!
We want to look at the package list right now without any delays!
Our solution is the following: we create a local packages cache.
Of course, we don’t want to use a lot of storage space.
So, we keep only a few important fields per package (like Id, DownloadCount, IconUrl, and so on).
When you search a NuGet package in Rider, you always search in our cache!
That is why you have zero-latency typing in the NuGet manager.
The NuGet package cache is persisted between Rider sessions. Free bonus: if you launch Rider the second time, you already have a warmed cache. The search will work as soon as the NuGet component was initialized without additional network requests.
Fetching
Ok, we can take data for search results from cache. However, we still have to fetch the metadata of packages from a remote feed. Let’s introduce fetchers. Each fetcher can handle fetch requests of a special kind to a specific feed There are several interesting decisions about fetchers.
Rider allows searching the same package in several feeds. Each feed can have own request latency. We want to show top packages into the cache as soon as possible, and we can’t allow feeds with low latency affect other feeds. So, we have a separated set of fetchers per feed.
Next, we create two fetchers per feed: one for the general search and one for fetching metadata of a specific package. It allows updating information about installed packages (some of them can have updates) and information about a selected package (which should be shown on the right panel) in the background: it doesn’t affect the search process.
Each search fetcher should fetch information about a big amount of packages. By default, we are fetching the top 300 packages for each search term. However, we can’t ask for 300 packages at once: such request has huge latency. It will take a lot of time before we can update our cache. We also can’t ask several times for one package one after the other because each request (even we ask for only one package) also has some minimum latency. Thus, we found a trade-off: we ask 30 times for a ten package batch. Maybe there are better values, but it’s a point for future investigation. Current values work pretty well for now.
Thus, we have a queue of requests.
Internally, it’s an asynchronous mergeable queue with priorities.
Each request has
searchTerm (what are we looking for),
skip (how many packages we should skip),
take (how many packages we should take),
and a few additional flags.
When you open the NuGet windows for the first time and the search box text is empty, the queue looks like this:
'' Skip=0, Take=10
'' Skip=10, Take=10
'' Skip=20, Take=10
'' Skip=30, Take=10
'' Skip=40, Take=10
// ...
'' Skip=280, Take=10
'' Skip=290, Take=10
When you start to type some text, we add additional 30 requests per typed symbol.
So, if you open the NuGet window, type "ab", press backspace, then the queue will look like this:
'' Skip=0, Take=10
'' Skip=10, Take=10
'' Skip=20, Take=10
'' Skip=30, Take=10
'' Skip=40, Take=10
// ...
'' Skip=280, Take=10
'' Skip=290, Take=10
'a' Skip=0, Take=10
'a' Skip=10, Take=10
'a' Skip=20, Take=10
'a' Skip=30, Take=10
'a' Skip=40, Take=10
// ...
'a' Skip=280, Take=10
'a' Skip=290, Take=10
'ab' Skip=0, Take=10
'ab' Skip=10, Take=10
'ab' Skip=20, Take=10
'ab' Skip=30, Take=10
'ab' Skip=40, Take=10
// ...
'ab' Skip=280, Take=10
'ab' Skip=290, Take=10
'a' Skip=0, Take=10
'a' Skip=10, Take=10
'a' Skip=20, Take=10
'a' Skip=30, Take=10
'a' Skip=40, Take=10
// ...
'a' Skip=280, Take=10
'a' Skip=290, Take=10
The source code looks very simple: we just add additional requests and don’t think about anything. Internally, the queue is very smart; it can optimize this list before it starts to process the next request:
- The obsolete requests (
request.SearchTerm≠searchBox.Text) will be deleted. - The same requests will be merged.
- The rest of the requests will be sorted.
- The first request in the result list will be handled.
This queue has many additional nice features.
For example, each queue has its own local history.
If we already handled 30 requests for empty string,
next, we type "a",
press backspace,
new 30 requests for the empty string will not be handled:
the queue remembers that we already fetched all this information in the recent past.
Of course, each item in the local history has a timestamp,
so you shouldn’t be worried about obsolete results for cases
when remote packages were updated.
Smart search
Ok, we fetched all the packages and put them into the cache.
Now you should filter all the cached packages and sort them according to the searchTerm.
Here we use our awesome R# search engine.
For example, if I want to find "BenchmarkDotNet", I can type:
"BnechmarkDotNet": typos will be detected"BeDoNe": CamelHumps is supported"ИутсрьфклВщеТуе"or"BקמביצשרלDםאNקא": no problem if you forget to switch keyboard layout from Russian or Hebrew to English
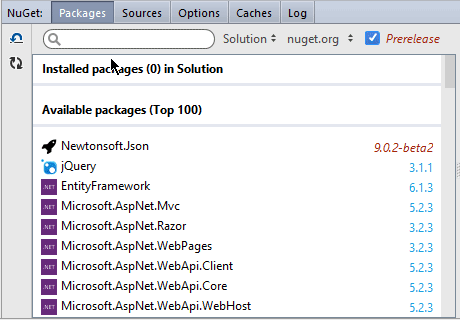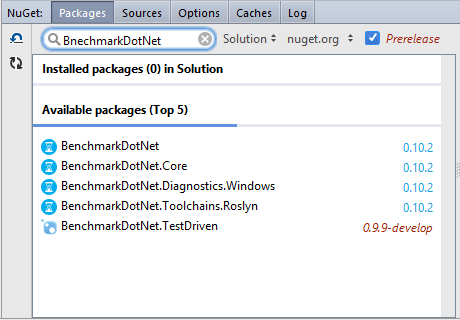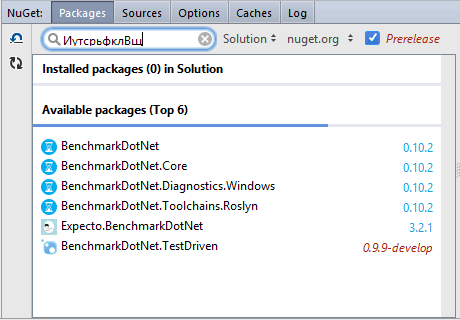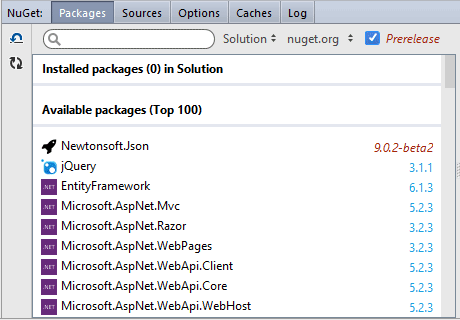
However, it’s not enough for the NuGet search.
For example, if I type "Json",
I probably want to find Newtonsoft.Json
instead of JSON.
So, we have a set of heuristics which try to improve sorting order and put the package which you really want to install in the first place.
For example, for the situation described above, we always move “popular” packages on the top.
But which package is “popular”?
It’s a very hard question especially when you are working with a custom set of packages which are matched to your searchTerm.
An obvious idea: we can sort all the matched packages by DownloadCount and take first N.
But how we should choose N?
It can not be a constant because our algorithm should work for sets of packages of any size (from 2 to thousands).
Popular packages could have
millions of downloads (like Newtonsoft.Json),
thousands of downloads or
even hundreds of downloads
(depends on particular set of packages).
You can come up with many different approaches, but here is our way:
- Build a sorted list of
DownloadCountvalues - Peek top 20
- Take the natural logarithm of each number
- Find the largest gap between two neighboring packages,
- All the packages before the gap are popular; they should be moved to the top of the list.
This algorithm can look strange and illogical, but it works very well. There is no perfect solution for such problems. So, we just try to create heuristics which work fast and somehow produce the result which you want in each specific situation.
Future development
For now, Rider is in the EAP stage, and there are many features that we want to implement before release. Some examples:
- Search by type and namespace. It’s hard to integrate such feature in our search engine, but we already have some cool ideas.
- Feed statistics: we want to get the detailed diagnostics information about each feed. It will allow to predict latency of each request and improve fetcher algorithms.
- Handle “slow” feeds: some private feeds can spend about 2 minutes(!) per one request (I don’t have any idea why). And it’s a big problem, so we should handle such feeds in a special way.
Conclusion
In this post, I covered only a few things which are implemented in our NuGet search engine. There are many technical details under the hood of the small NuGet search box. And we try to improve it all the time and create the best NuGet manager in the world. =) If you have any complaints or feature requests, you are welcome on our issue tracker. Your feedback is very important for us.