Trimmed Harrell-Davis quantile estimator based on the highest density interval of the given width
Traditional quantile estimators that are based on one or two order statistics are a common way to estimate distribution quantiles based on the given samples. These estimators are robust, but their statistical efficiency is not always good enough. A more efficient alternative is the Harrell-Davis quantile estimator which uses a weighted sum of all order statistics. Whereas this approach provides more accurate estimations for the light-tailed distributions, it’s not robust. To be able to customize the trade-off between statistical efficiency and robustness, we could consider a trimmed modification of the Harrell-Davis quantile estimator. In this approach, we discard order statistics with low weights according to the highest density interval of the beta distribution.
Introduction
We consider a problem of quantile estimation for the given sample. Let $x$ be a sample with $n$ elements: $x = \{ x_1, x_2, \ldots, x_n \}$. We assume that all sample elements are sorted ($x_1 \leq x_2 \leq \ldots \leq x_n$) so that we could treat the $i^\textrm{th}$ element $x_i$ as the $i^\textrm{th}$ order statistic $x_{(i)}$. Based on the given sample, we want to build an estimation of the $p^\textrm{th}$ quantile $Q(p)$.
The traditional way to do this is to use a single order statistic
or a linear combination of two subsequent order statistics.
This approach could be implemented in various ways.
A classification of the most popular implementations could be found in Sample Quantiles in Statistical Packages
By Rob J Hyndman, Yanan Fan
·
1996hyndman1996.
In this paper, Rob J. Hyndman and Yanan Fan describe nine types of traditional quantile estimators
which are used in statistical computer packages.
The most popular approach in this taxonomy is Type 7 which is used by default in R, Julia, NumPy, and Excel:
Traditional quantile estimators have simple implementations and a good robustness level.
However, their statistical efficiency is not always good enough:
the obtained estimations could noticeably differ from the true distribution quantile values.
The gap between the estimated and true values could be decreased by increasing the number of used order statistics.
In A new distribution-free quantile estimator
By Frank E Harrell, C E Davis
·
1982harrell1982, Frank E. Harrell and C. E. Davis suggest estimating quantiles using
a weighted sum of all order statistics:
where $I_x(\alpha, \beta)$ is the regularized incomplete beta function, $\alpha = (n+1)p$, $\;\beta = (n+1)(1-p)$. To get a better understanding of this approach, we could look at the probability density function of the beta distribution $\operatorname{Beta}(\alpha, \beta)$. If we split the $[0;1]$ interval into $n$ segments of equal width, we can define $W_{\operatorname{HD},i}$ as the area under curve in the $i^\textrm{th}$ segment. Since $I_x(\alpha, \beta)$ is the cumulative distribution function of $\operatorname{Beta}(\alpha, \beta)$, we can express $W_{\operatorname{HD},i}$ as $I_{i/n}(\alpha, \beta) - I_{(i-1)/n}(\alpha, \beta)$.
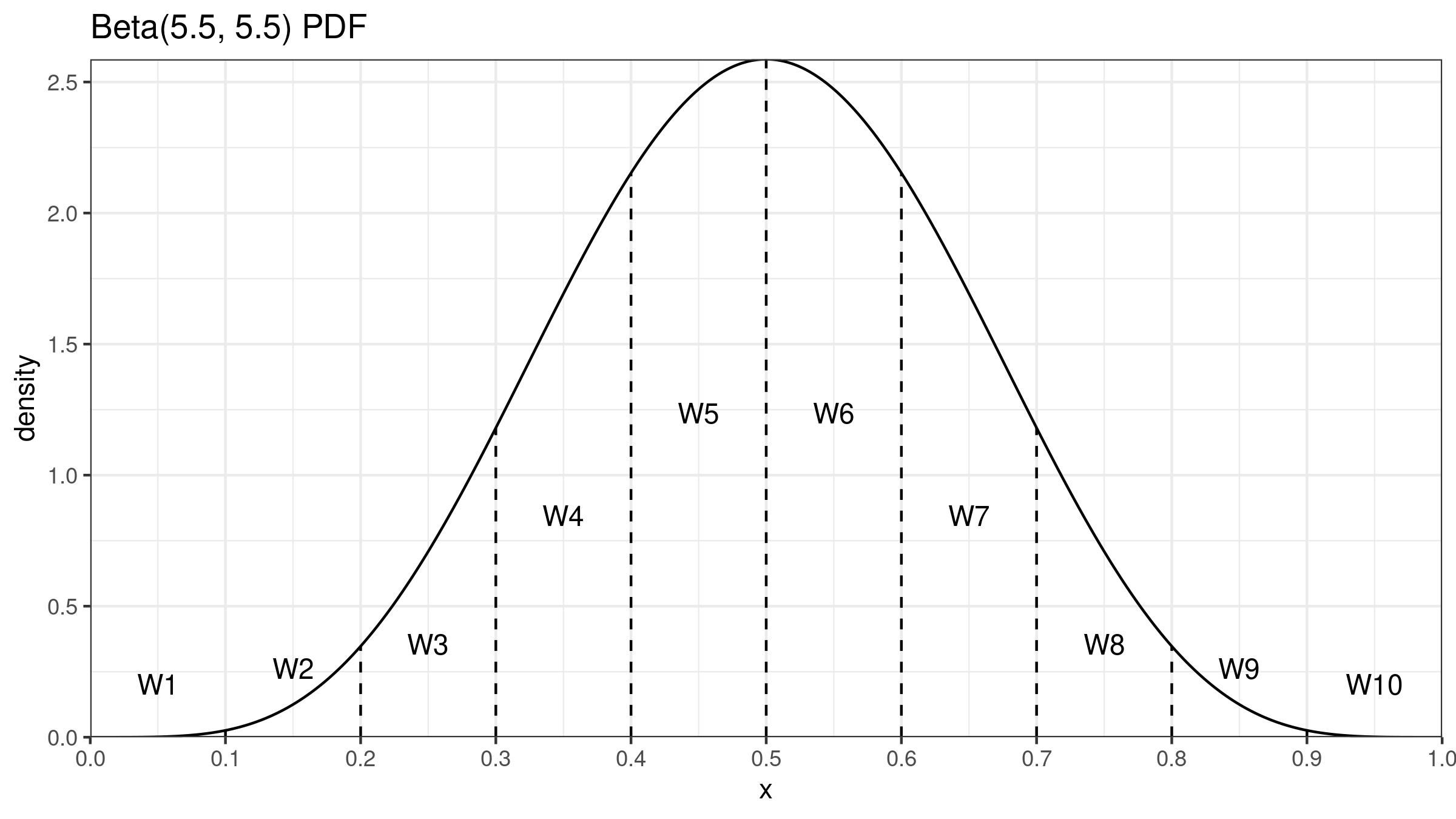

The Harrell-Davis quantile estimator shows decent statistical efficiency in the case of light-tailed distributions: its estimations are much more precise than estimations of the traditional quantile estimators. However, the improved efficiency has a price: $Q_{\operatorname{HD}}$ is not robust. Since the estimation is a weighted sum of all order statistics with positive weights, a single corrupted element may spoil all the quantile estimations, including the median. It may become a severe drawback in the case of heavy-tailed distributions in which it’s a typical situation when we have a few extremely large outliers. In such cases, we use the median instead of the mean as a measure of central tendency because of its robustness. Indeed, if we estimate the median using the traditional quantile estimators like $Q_{\operatorname{HF7}}$, its asymptotical breakdown point is 0.5. Unfortunately, if we switch to $Q_{\operatorname{HD}}$, the breakdown point becomes zero so that we completely lose the median robustness.
Another severe drawback of $Q_{\operatorname{HD}}$ is its computational complexity. If we have a sorted array of numbers, a traditional quantile estimation could be computed using $O(1)$ simple operations. If we estimate the quantiles using $Q_{\operatorname{HD}}$, we need $O(n)$ operations. Moreover, these operations involve computation of $I_x(\alpha, \beta)$ values which are pretty expensive from the computational point of view. If we want to estimate millions of quantile estimations, $Q_{\operatorname{HD}}$ may have a noticeable impact on the application performance.
Neither $Q_{\operatorname{HF7}}$ nor $Q_{\operatorname{HD}}$ fit all kinds of problem. $Q_{\operatorname{HF7}}$ is simple, robust, and computationally fast, but its statistical efficiency doesn’t always satisfy the business requirements. $Q_{\operatorname{HD}}$ could provide better statistical efficiency, but it’s computationally slow and not robust.
To get a reasonable trade-off between $Q_{\operatorname{HF7}}$ and $Q_{\operatorname{HD}}$, we consider a trimmed modification of the Harrell-Davis quantile estimator. The core idea is simple: we take the classic Harrell-Davis quantile estimator, find the highest density interval of the underlying beta distribution, discard all the order statistics outside the interval, and calculate a weighted sum of the order statistics within the interval. The obtained quantile estimation is more robust than $Q_{\operatorname{HD}}$ (because it doesn’t use extreme values) and typically more statistically efficient than $Q_{\operatorname{HF7}}$ (because it uses more than only two order statistics). Let’s discuss this approach in detail.
The trimmed Harrell-Davis quantile estimator
The estimators based on one or two order statistics are not efficient enough because they use too few sample elements. The estimators based on all order statistics are not robust enough because they use too many sample elements. It looks reasonable to consider a quantile estimator based on a variable number of order statistics. This number should be large enough to ensure decent statistical efficiency but not too large to exclude possible extreme outliers.
A robust alternative to the mean is the trimmed mean. The idea behind it is simple: we should discard some sample elements at both ends and use only the middle order statistics. With this approach, we can customize the trade-off between robustness and statistical efficiency by controlling the number of the discarded elements. If we apply the same idea to $Q_{\operatorname{HD}}$, we can build a trimmed modification of the Harrell-Davis quantile estimator. Let’s denote it as $Q_{\operatorname{THD}}$.
In the case of the trimmed mean, we typically discard the same number of elements on each side. We can’t do the same for $Q_{\operatorname{THD}}$ because the array of order statistic weights $\{ W_{\operatorname{HD},i} \}$ is asymmetric. It looks reasonable to drop the elements with the lowest weights and keep the elements with the highest weights. Since the weights are assigned according to the beta distribution, the range of order statistics with the highest weight concentration could be found using the beta distribution highest density interval. Thus, once we fix the proportion of dropped/kept elements, we should find the highest density interval of the given width. Let’s denote the interval as $[L;R]$ where $R-L=D$. The order statistics weights for $Q_{\operatorname{THD}}$ should be defined using a part of the beta distribution within this interval. It gives us the truncated beta distribution $\operatorname{TBeta}(\alpha, \beta, L, R)$:
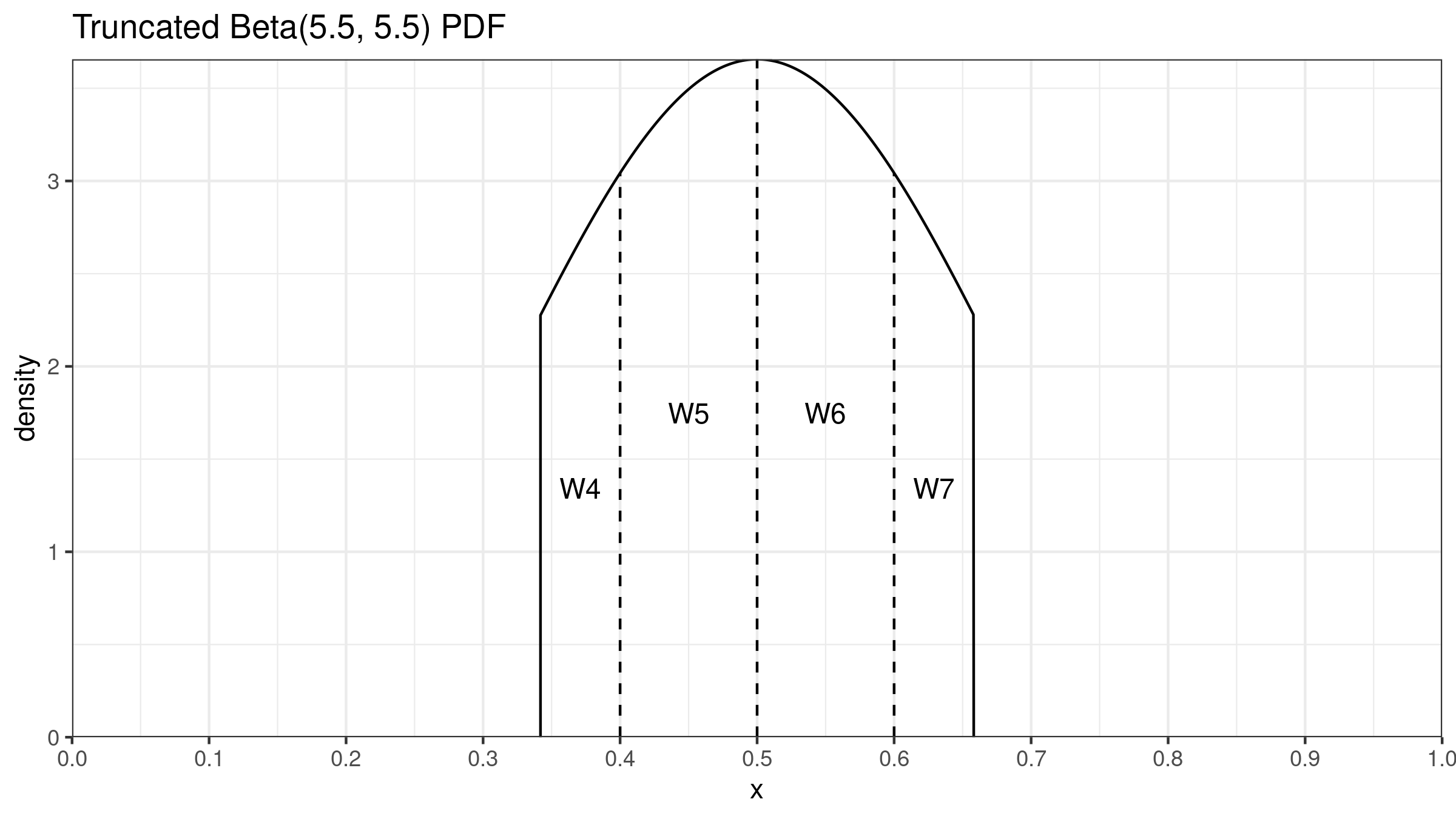

We know the CDF for $\operatorname{Beta}(\alpha, \beta)$ which is used in $Q_{\operatorname{HD}}$: $F_{\operatorname{HD}}(x) = I_x(\alpha, \beta)$. For $Q_{\operatorname{THD}}$, we need the CDF for $\operatorname{TBeta}(\alpha, \beta, L, R)$ which could be easily found:
$$ F_{\operatorname{THD}}(x) = \begin{cases} 0 & \textrm{for }\, x < L,\\ \big( F_{\operatorname{HD}}(x) - F_{\operatorname{HD}}(L) \big) / \big( F_{\operatorname{HD}}(R) - F_{\operatorname{HD}}(L) \big) & \textrm{for }\, L \leq x \leq R,\\ 1 & \textrm{for }\, R < x. \end{cases} $$The final $Q_{\operatorname{THD}}$ equation has the same form as $Q_{\operatorname{HD}}$:
$$ Q_{\operatorname{THD}} = \sum_{i=1}^{n} W_{\operatorname{THD},i} \cdot x_i, \quad W_{\operatorname{THD},i} = F_{\operatorname{THD}}(i / n) - F_{\operatorname{THD}}((i - 1) / n). $$There is only one thing left to do: we should choose an appropriate width $D$ of the beta distribution highest density interval. In practical application, this value should be chosen based on the given problem: researchers should carefully analyze business requirements, describe desired robustness level via setting the breakdown point, and come up with a $D$ value that satisfies the initial requirements.
However, if we have absolutely no information about the problem, the underlying distribution, and the robustness requirements, we can use the following rule of thumb which gives the starting point: $D=1/\sqrt{n}$. We denote $Q_{\operatorname{THD}}$ with such a $D$ value as $Q_{\operatorname{THD-SQRT}}$. In most cases, it gives an acceptable trade-off between the statistical efficiency and the robustness level. Also, $Q_{\operatorname{THD-SQRT}}$ has a practically reasonable computational complexity: $O(\sqrt{n})$ instead of $O(n)$ for $Q_{\operatorname{HD}}$. For example, if $n=10000$, we have to process only 100 sample elements and calculate 101 values of $I_x(\alpha, \beta)$.
An example Let’s say we have the following sample:
$$ x = \{ -0.565, -0.106, -0.095, 0.363, 0.404, 0.633, 1.371, 1.512, 2.018, 100\,000 \}. $$Nine elements were randomly taken from the standard normal distribution $\mathcal{N}(0, 1)$. The last element $x_{10}$ is an outlier. The weight coefficient for $Q_{\operatorname{HD}}$ an $Q_{\operatorname{THD-SQRT}}$ are presented in the following table:
| $i$ | $x_i$ | $W_{\operatorname{HD},i}$ | $W_{\operatorname{THD-SQRT},i}$ |
|---|---|---|---|
| 1 | -0.565 | 0.0005 | 0 |
| 2 | -0.106 | 0.0146 | 0 |
| 3 | -0.095 | 0.0727 | 0 |
| 4 | 0.363 | 0.1684 | 0.1554 |
| 5 | 0.404 | 0.2438 | 0.3446 |
| 6 | 0.633 | 0.2438 | 0.3446 |
| 7 | 1.371 | 0.1684 | 0.1554 |
| 8 | 1.512 | 0.0727 | 0 |
| 9 | 2.018 | 0.0146 | 0 |
| 10 | 100000.000 | 0.0005 | 0 |
Here are the corresponding quantile estimations:
$$ Q_{\operatorname{HD}}(0.5) \approx 51.9169, \quad Q_{\operatorname{THD}}(0.5) \approx 0.6268. $$As we can see, $Q_{\operatorname{HD}}$ is heavily affected by the outlier $x_{10}$. Meanwhile, $Q_{\operatorname{THD}}$ gives a reasonable median estimation because it uses a weighted sum of four middle order statistics.
Beta distribution highest density interval of the given width
In order to build the truncated beta distribution for $Q_{\operatorname{THD}}$, we have to find the $\operatorname{Beta}(\alpha, \beta)$ highest density interval of the required width $D$. Thus, for the given $\alpha, \beta, D$, we should provide an interval $[L;R]$:
$$ \operatorname{BetaHDI}(\alpha, \beta, D) = [L; R]. $$Let’s briefly discuss how to do this. First of all, we should calculate the mode $M$ of $\operatorname{Beta}(\alpha, \beta)$:
$$ M = \operatorname{Mode}_{\alpha, \beta} = \begin{cases} \{0, 1 \} \textrm{ or any value in } (0, 1) & \textrm{for }\, \alpha \leq 1,\, \beta \leq 1, & \textit{(Degenerate case)} 0 & \textrm{for }\, \alpha \leq 1,\, \beta > 1, & \textit{(Left border case)} \\ 1 & \textrm{for }\, \alpha > 1,\, \beta \leq 1, & \textit{(Right border case)} \\ \frac{\alpha - 1}{\alpha + \beta - 2} & \textrm{for }\, \alpha > 1,\, \beta > 1. & \textit{(Middle case)} \\ \end{cases} $$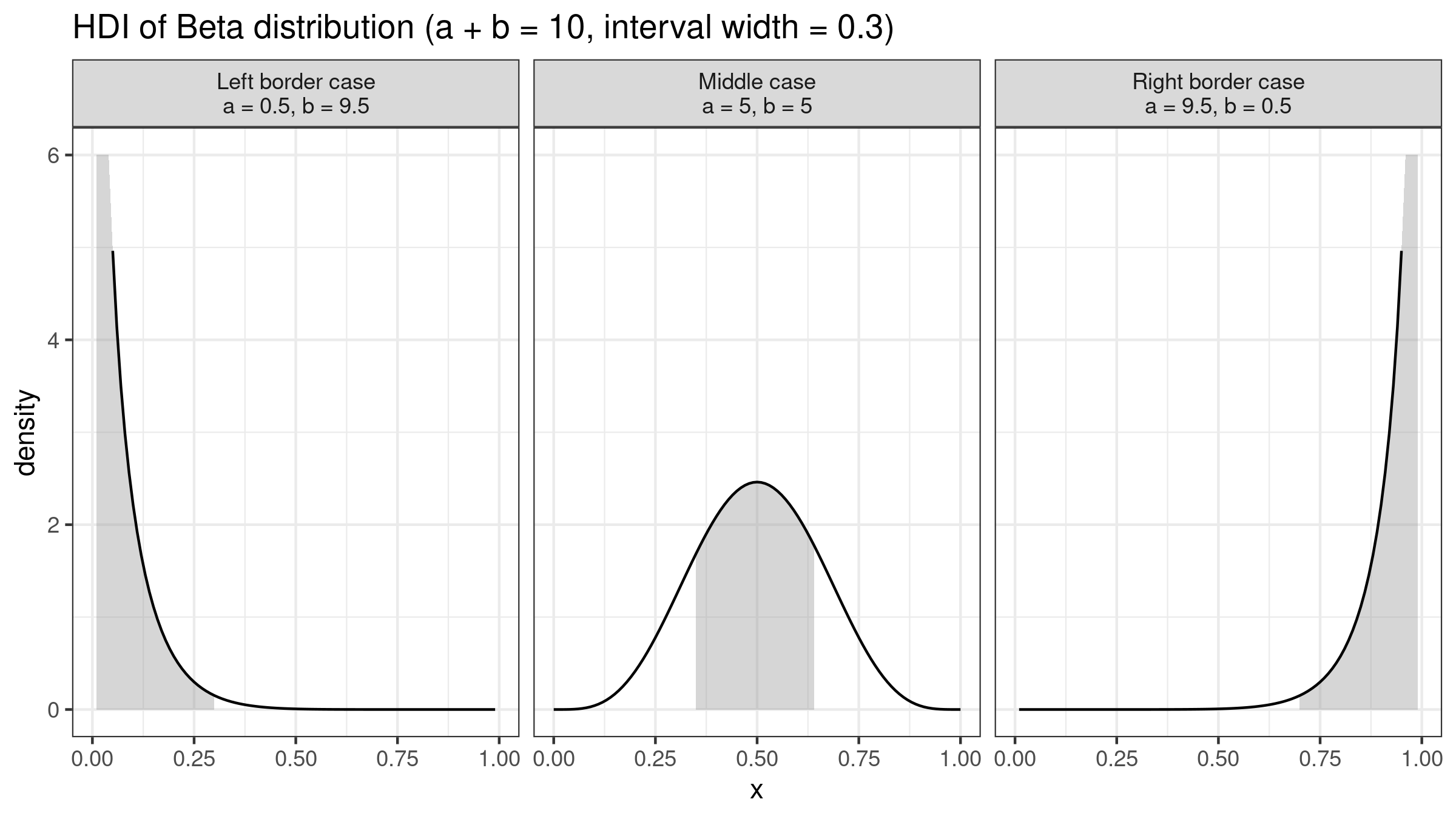
The actual value of $\operatorname{BetaHDI}(\alpha, \beta, D)$ depends on the specific case from the above list which defines the mode location. Three of these cases are easy to handle:
- Degenerate case $\alpha \leq 1, \beta \leq 1$: There is only one way to get such a situation: $n = 1, p = 0.5$. Since such a sample contains a single element, it doesn’t matter how we choose the interval.
- Left border case $\alpha \leq 1, \, \beta > 1$: The mode equals zero, so the interval should be “attached to the left border”: $\operatorname{BetaHDI}(\alpha, \beta, D) = [0; D]$.
- Right border case $\alpha > 1, \, \beta \leq 1$: The mode equals one, so the interval should be “attached to the right border”: $\operatorname{BetaHDI}(\alpha, \beta, D) = [1 - D; 1]$
The fourth case is the middle case ($\alpha > 1,\, \beta > 1$), the HDI should be inside $(0;1)$. Since the density function of the beta distribution is a unimodal function, it consists of two segments: a monotonically increasing segment $[0, M]$ and a monotonically decreasing segment $[M, 1]$. The HDI $[L;R]$ should contain the mode, so
$$ L \in [0; M], \quad R \in [M; 1]. $$Since $R - L = D$, we could also conclude that
$$ L = R - D \in [M - D; 1 - D], \quad R = L + D \in [D; M + D]. $$Thus,
$$ L \in [\max(0, M - D);\; \min(M, 1 - D)], \quad R \in [\max(M, D);\; \min(1, M + D)]. $$The density function of the beta distribution is also known:
$$ f(x) = \dfrac{x^{\alpha - 1} (1 - x)^{\beta - 1}}{\textrm{B}(\alpha, \beta)}, \quad \textrm{B}(\alpha, \beta) = \dfrac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha + \beta)}. $$It’s easy to see that for the highest density interval $[L; R]$, the following condition is true:
$$ f(L) = f(R). $$The left border $L$ of this interval could be found as a solution of the following equation:
$$ f(t) = f(t + D), \quad \textrm{where }\, t \in [\max(0, M - D);\; \min(M, 1 - D)]. $$The left side of the equation is monotonically increasing, the right side is monotonically decreasing. The equation has exactly one solution which could be easily found numerically using the binary search algorithm.
Simulation study
Let’s perform a few numerical simulations and see how $Q_{\operatorname{THD}}$ works in action.
Simulation 1
Let’s explore the distribution of estimation errors of $Q_{\operatorname{HF7}}$, $Q_{\operatorname{HD}}$, and $Q_{\operatorname{THD-SQRT}}$. We consider a contaminated normal distribution which is a mixture of two normal distributions: $(1 - \varepsilon)\mathcal{N}(0, \sigma^2) + \varepsilon\mathcal{N}(0, c\sigma^2)$. For our simulation, we use $\varepsilon = 0.01,\; \sigma = 1,\; c = 1\,000\,000$. We generate $10\,000$ samples of size 7 randomly taken from the considered distribution. For each sample, we estimate the median using $Q_{\operatorname{HF7}}$, $Q_{\operatorname{HD}}$, and $Q_{\operatorname{THD-SQRT}}$. Thus, we have $10\,000$ of median estimations for each estimator. Next, we evaluate lower and higher percentiles for each group of estimations. The results are presented in the following table:
| quantile | HF7 | HD | THD-SQRT |
|---|---|---|---|
| 0.00 | -1.6921648 | -87.6286082 | -1.6041220 |
| 0.01 | -1.1054591 | -9.8771723 | -1.0261234 |
| 0.02 | -0.9832125 | -5.2690083 | -0.9067884 |
| 0.03 | -0.9037046 | -1.7742334 | -0.8298706 |
| 0.04 | -0.8346268 | -0.9921591 | -0.7586603 |
| 0.05 | -0.7773634 | -0.8599139 | -0.7141364 |
| 0.95 | 0.7740584 | 0.8062170 | 0.7060375 |
| 0.96 | 0.8172518 | 0.8964743 | 0.7540437 |
| 0.97 | 0.8789283 | 1.1240294 | 0.8052421 |
| 0.98 | 0.9518048 | 4.3675475 | 0.8824462 |
| 0.99 | 1.0806293 | 10.4132583 | 0.9900912 |
| 1.00 | 2.0596785 | 140.5802861 | 1.7060750 |
As we can see, approximately 2% of all $Q_{\operatorname{HD}}$ results exceed 10 by their absolute values (while the true median value is zero). Meanwhile, the maximum absolute value of the $Q_{\operatorname{THD-SQRT}}$ median estimations is approximately $1.7$. Thus, $Q_{\operatorname{THD-SQRT}}$ is much more resistant to outliers than $Q_{\operatorname{HD}}$.
Simulation 2
Let’s compare the statistical efficiency of $Q_{\operatorname{HD}}$ and $Q_{\operatorname{THD}}$. We evaluate the relative efficiency of these estimators against $Q_{\operatorname{HF7}}$ which is a conventional baseline in such experiments. For the $p^\textrm{th}$ quantile, the classic relative efficiency can be calculated as the ratio of the estimator mean squared errors ($\operatorname{MSE}$):
$$ \operatorname{Efficiency}(p) = \dfrac{\operatorname{MSE}(Q_{HF7}, p)}{\operatorname{MSE}(Q_{\textrm{Target}}, p)} = \dfrac{\operatorname{E}[(Q_{HF7}(p) - \theta(p))^2]}{\operatorname{E}[(Q_{\textrm{Target}}(p) - \theta(p))^2]}, $$where $\theta(p)$ is the true quantile value. We conduct this simulation according to the following scheme:
- We consider a bunch of different symmetric and asymmetric, light-tailed and heavy-tailed distributions.
- We enumerate all the percentile values $p$ from 0.01 to 0.99.
- For each distribution, we generate 200 random samples of the given size. For each sample, we estimate the $p^\textrm{th}$ percentile using $Q_{\operatorname{HF7}}$, $Q_{\operatorname{HD}}$, and $Q_{\operatorname{THD-SQRT}}$. For each estimator, we calculate the arithmetic average of $(Q(p) - \theta(p))^2$.
- $\operatorname{MSE}$ is not a robust metric, so we wouldn’t get reproducible output in such an experiment. To achieve more stable results, we repeat the previous step 101 times and take the median across $\operatorname{E}[(Q(p) - \theta(p))^2]$ values for each estimator. This median is our estimation of $\operatorname{MSE}(Q, p)$.
- We evaluate the relative efficiency of $Q_{\operatorname{HD}}$ and $Q_{\operatorname{THD-SQRT}}$ against $Q_{\operatorname{HF7}}$.
Here are the results of this simulation for $n=\{5, 10, 20\}$:
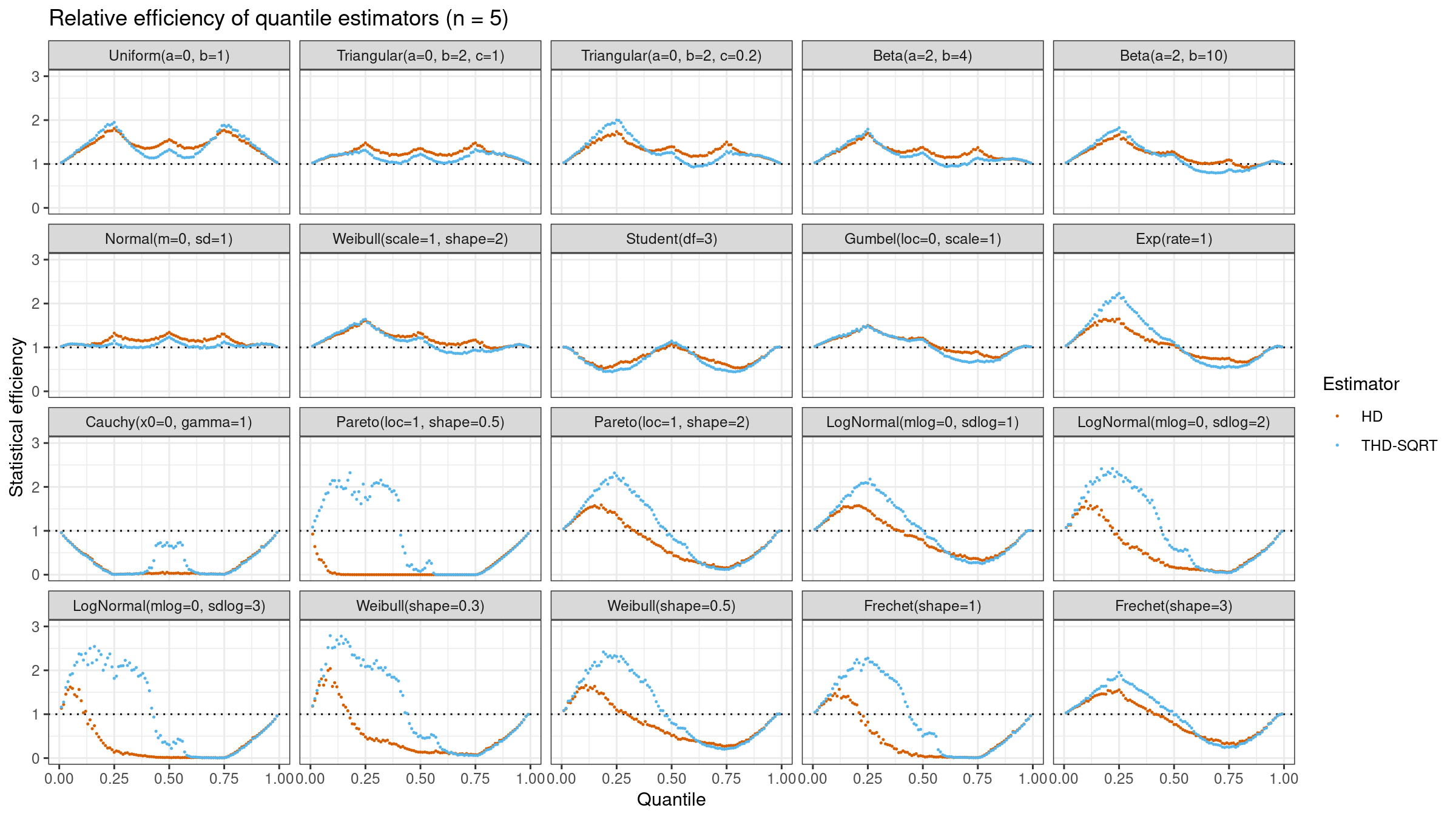
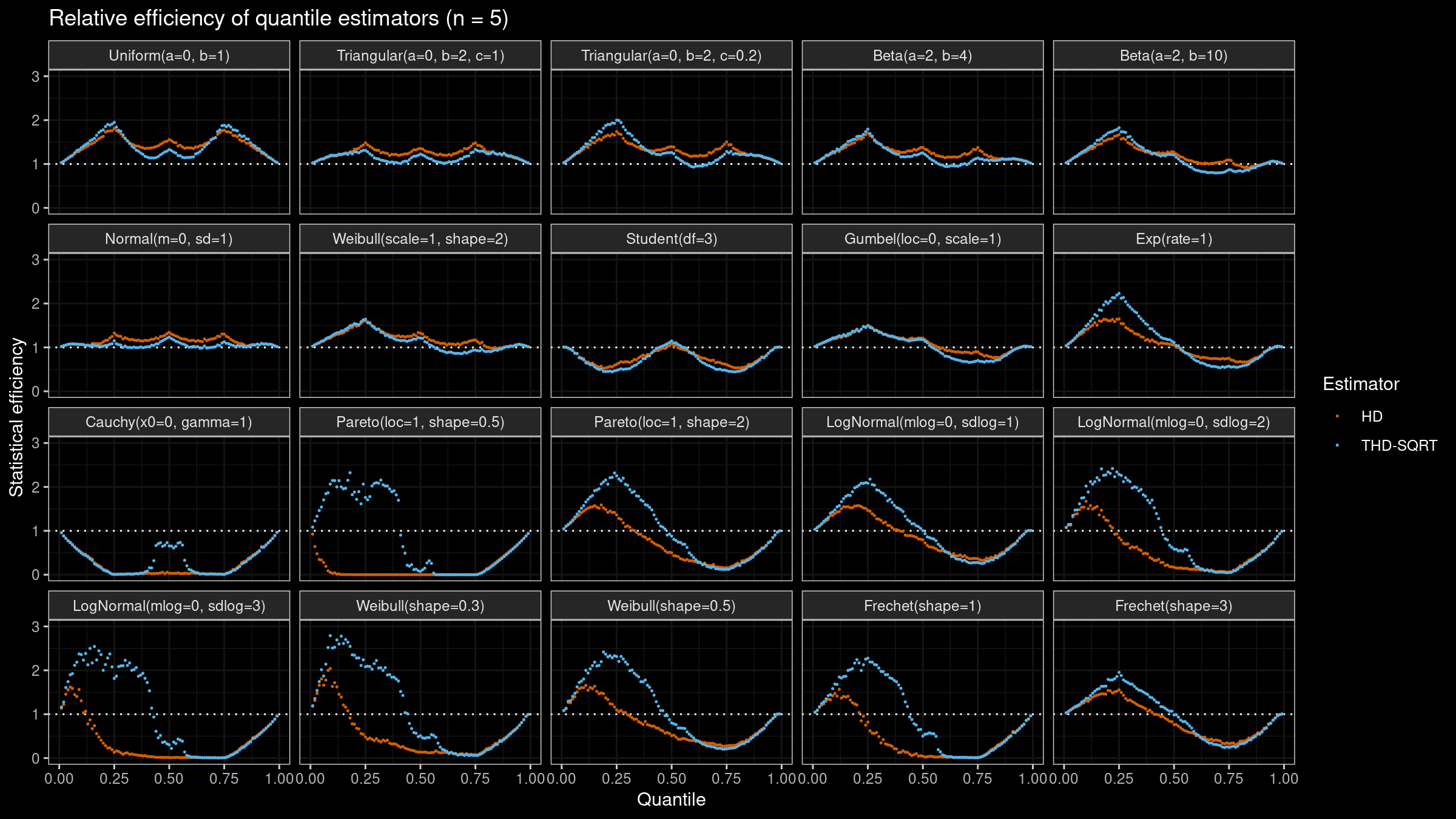
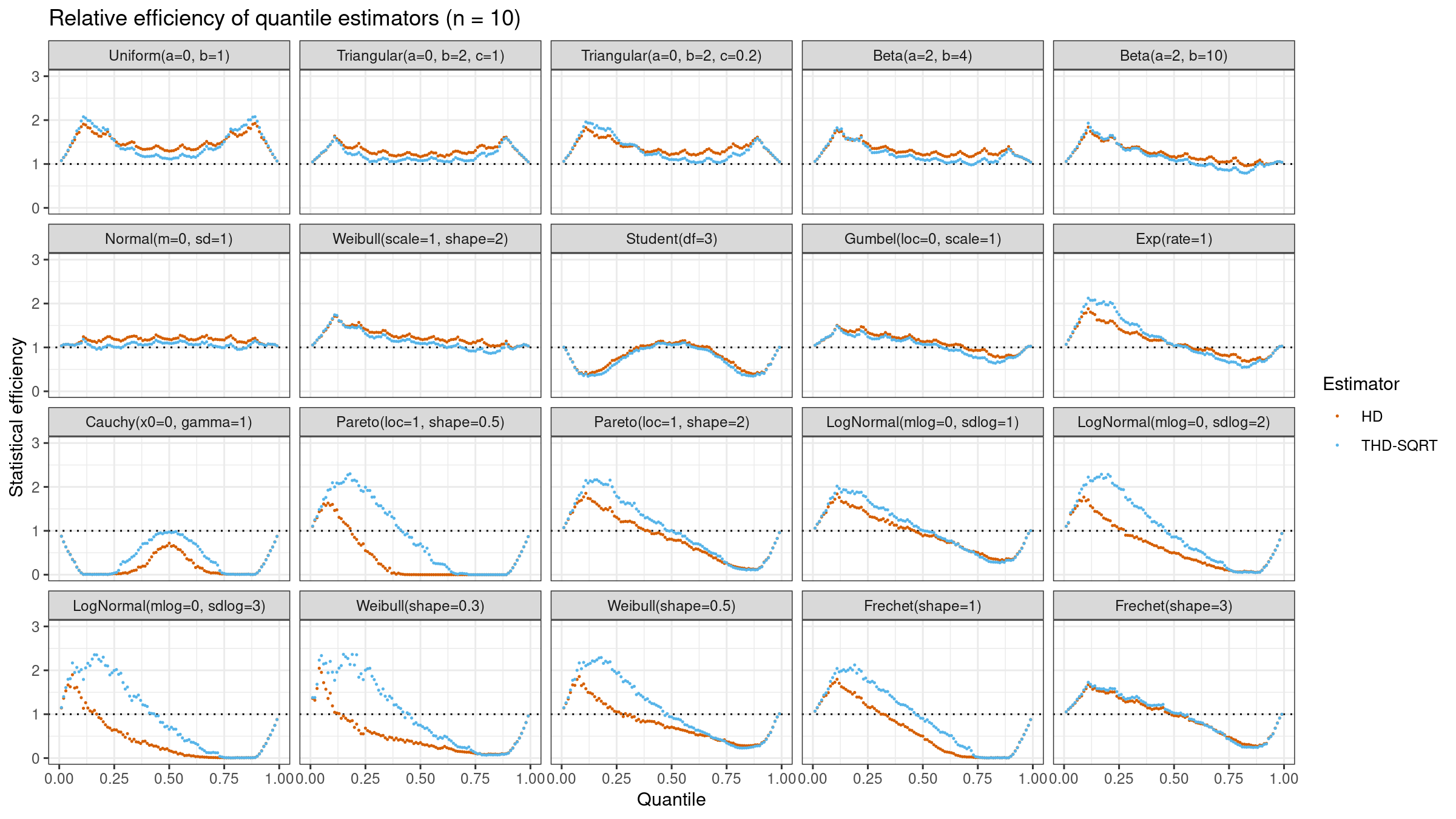
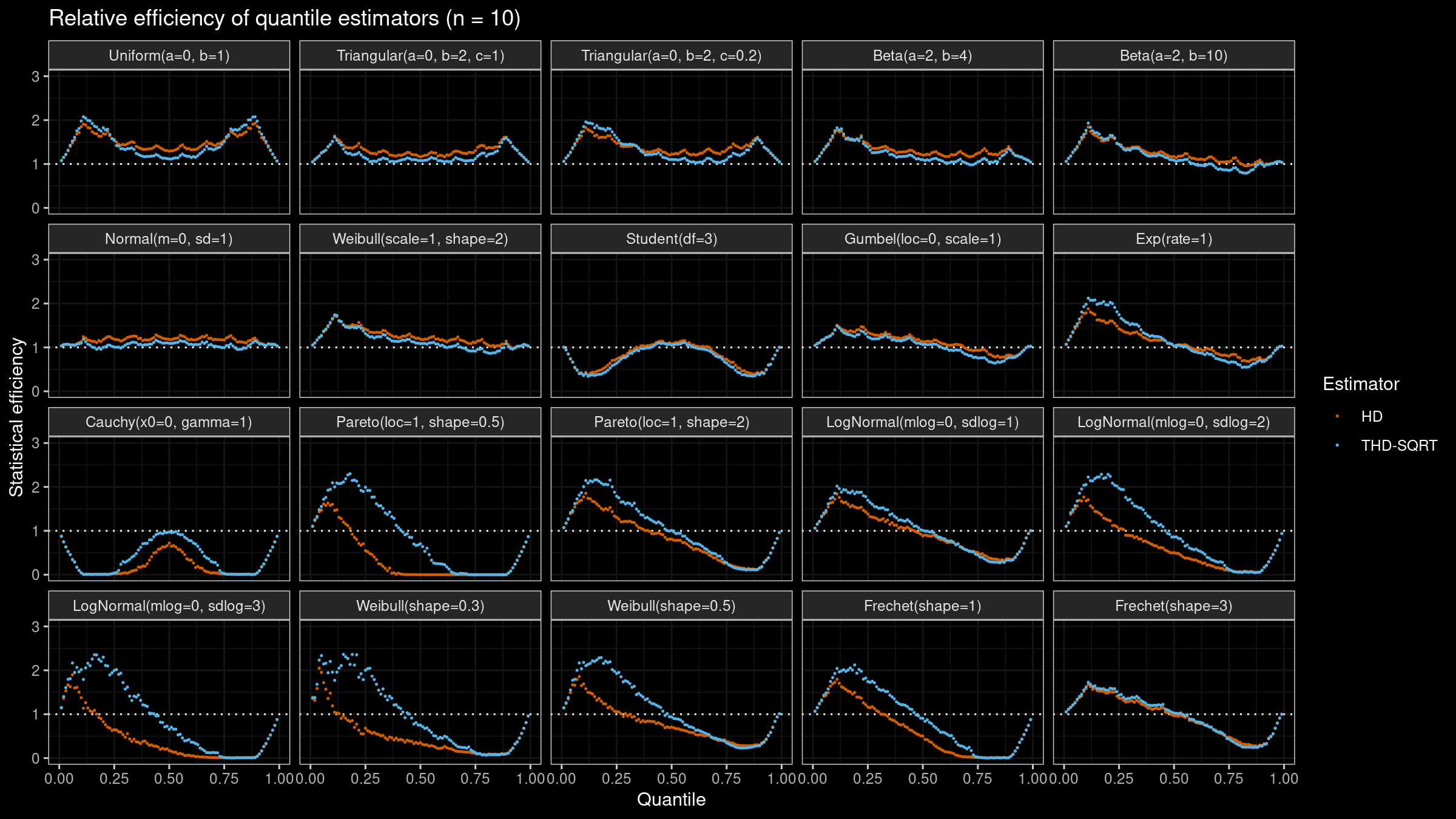
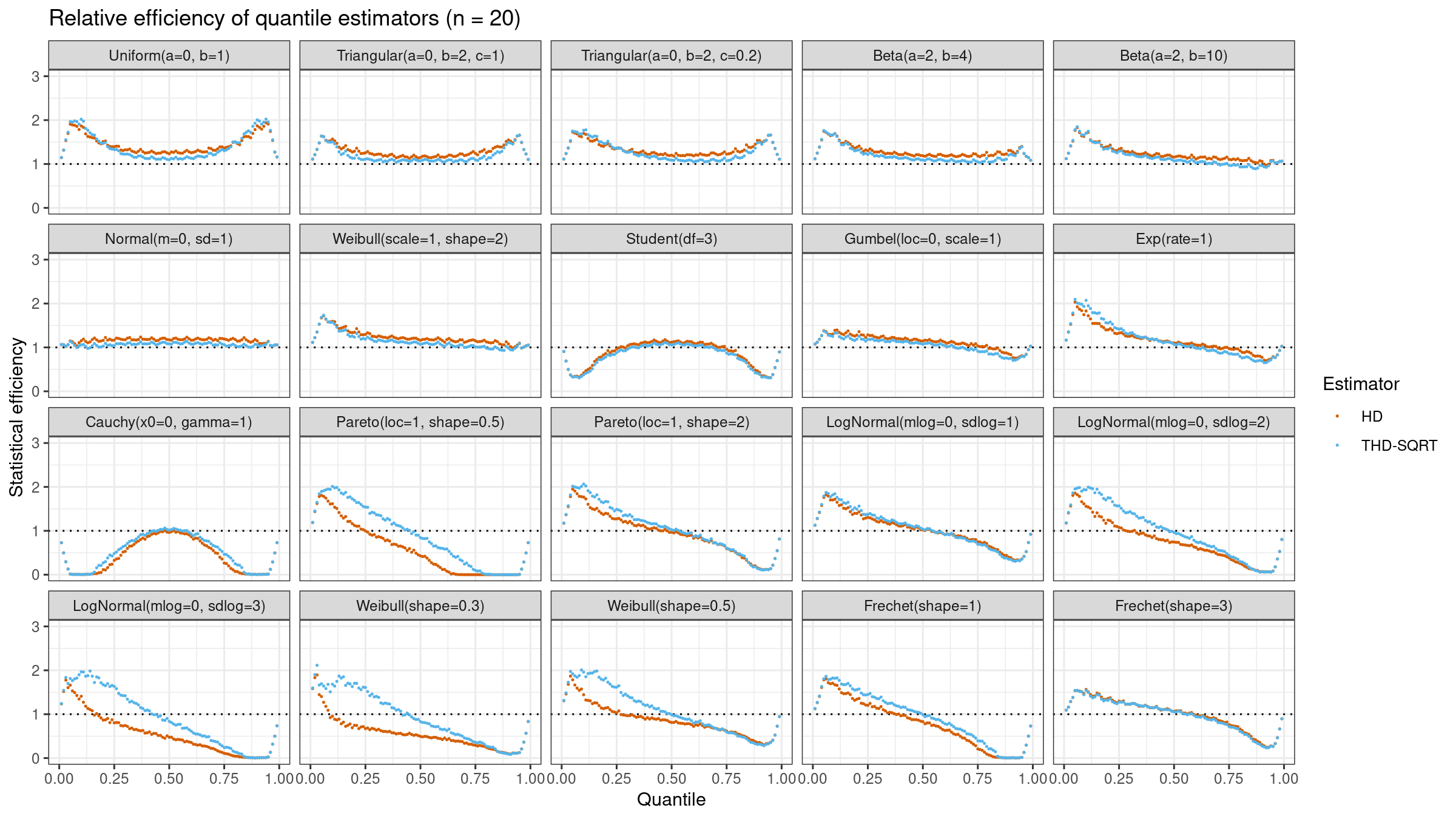
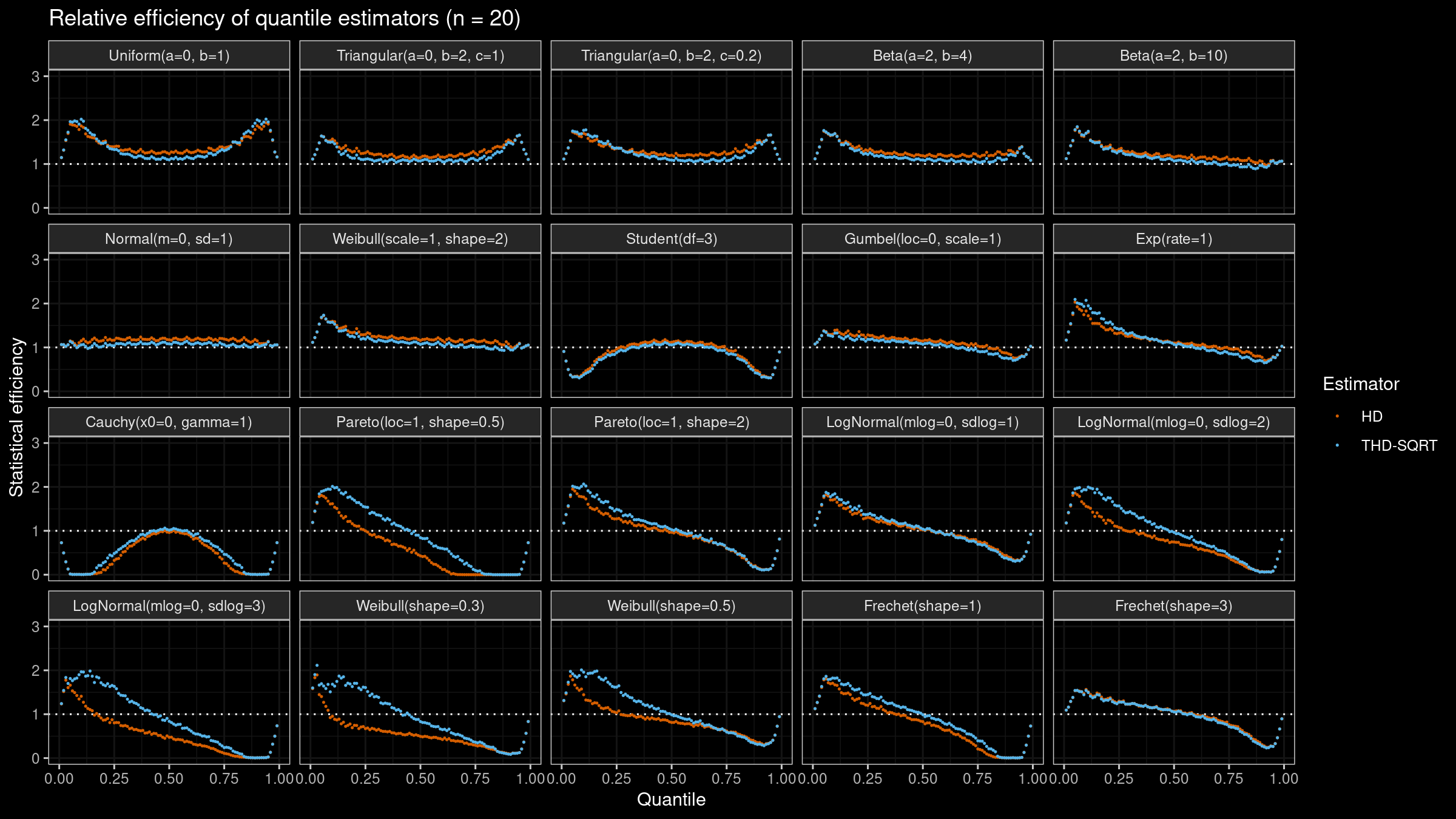
As we can see, $Q_{\operatorname{THD-SQRT}}$ is not so efficient as $Q_{\operatorname{HD}}$ in the case of light-tailed distributions. However, in the case of heavy-tailed distributions, $Q_{\operatorname{THD-SQRT}}$ has better efficiency than $Q_{\operatorname{HD}}$ because estimations of $Q_{\operatorname{HD}}$ are corrupted by outliers.
Conclusion
There is no perfect quantile estimator that fits all kinds of problems. The choice of a specific estimator has to be made based on the knowledge of the domain area and the properties of the target distributions. $Q_{\operatorname{HD}}$ is a good alternative to $Q_{\operatorname{HF7}}$ in the light-tailed distributions because it has higher statistical efficiency. However, if extreme outliers may appear, estimations of $Q_{\operatorname{HD}}$ could be heavily corrupted. $Q_{\operatorname{THD}}$ could be used as a reasonable trade-off between $Q_{\operatorname{HF7}}$ and $Q_{\operatorname{HD}}$. In most cases, $Q_{\operatorname{THD}}$ has better efficiency than $Q_{\operatorname{HF7}}$ and it’s also more resistant to outliers than $Q_{\operatorname{HD}}$. By customizing the width $D$ of the highest density interval, we could set the desired breakdown point according to the research goals. Also, $Q_{\operatorname{THD}}$ has better computational efficiency than $Q_{\operatorname{HD}}$ which makes it a faster option in practical applications.
Reference implementation
Here is an R implementation of the suggested estimator:
getBetaHdi <- function(a, b, width) {
eps <- 1e-9
if (a < 1 + eps & b < 1 + eps) # Degenerate case
return(c(NA, NA))
if (a < 1 + eps & b > 1) # Left border case
return(c(0, width))
if (a > 1 & b < 1 + eps) # Right border case
return(c(1 - width, 1))
if (width > 1 - eps)
return(c(0, 1))
# Middle case
mode <- (a - 1) / (a + b - 2)
pdf <- function(x) dbeta(x, a, b)
l <- uniroot(
f = function(x) pdf(x) - pdf(x + width),
lower = max(0, mode - width),
upper = min(mode, 1 - width),
tol = 1e-9
)$root
r <- l + width
return(c(l, r))
}
thdquantile <- function(x, probs, width = 1 / sqrt(length(x))) sapply(probs, function(p) {
n <- length(x)
if (n == 0) return(NA)
if (n == 1) return(x)
x <- sort(x)
a <- (n + 1) * p
b <- (n + 1) * (1 - p)
hdi <- getBetaHdi(a, b, width)
hdiCdf <- pbeta(hdi, a, b)
cdf <- function(xs) {
xs[xs <= hdi[1]] <- hdi[1]
xs[xs >= hdi[2]] <- hdi[2]
(pbeta(xs, a, b) - hdiCdf[1]) / (hdiCdf[2] - hdiCdf[1])
}
iL <- floor(hdi[1] * n)
iR <- ceiling(hdi[2] * n)
cdfs <- cdf(iL:iR/n)
W <- tail(cdfs, -1) - head(cdfs, -1)
sum(x[(iL+1):iR] * W)
})
A C# implementation could be found in perfolizer 0.3.0-nightly.105+.
References
- [Hyndman1996]
Hyndman, R. J. and Fan, Y. 1996. Sample quantiles in statistical packages, American Statistician 50, 361–365.
https://doi.org/10.2307/2684934 - [Harrell1982]
Harrell, F.E. and Davis, C.E., 1982. A new distribution-free quantile estimator. Biometrika, 69(3), pp.635-640.
https://doi.org/10.2307/2335999