Weighted quantile estimators
A slightly adjusted version of akinshin2023wqe.
Abstract
We consider a generic scheme that allows building weighted versions of various quantile estimators, such as traditional quantile estimators based on linear interpolation of two order statistics, the Harrell–Davis quantile estimator and its trimmed modification. The obtained weighted quantile estimators are especially useful in the problem of estimating a distribution at the tail of a time series using quantile exponential smoothing. The presented approach can also be applied to other problems, such as quantile estimation of weighted mixture distributions.
Introduction
We consider the problem of quantile estimation for a weighted sample. While this problem arises in different contexts, our primary focus is quantile exponential smoothing. For the given time series, we are interested in the quantiles of the distribution at the tail of the series, which reflects the latest state of the underlying system. Exponential smoothing suggests assigning weights to sample elements according to the exponential decay law (the newest measurements get the highest weights, and the oldest measurements get the lowest weights). A weighted quantile estimator is needed to obtain values of moving quantiles with a reasonable trade-off between the accuracy of estimations and resistance to obsolete measurements. Our secondary focus is on the problem of mixture distribution quantile estimation based on samples from individual distributions.
There are multiple existing weighted quantile estimators, such as quantile estimator of a weighted mixture distribution based on quantiles of individual samples, weighted kernel density estimation, weighted quantile estimations based on a linear combination of two order statistics. Unfortunately, all of these approaches have limitations, and they are not always applicable to quantile exponential smoothing.
We present a new approach that allows building weighted versions of existing non-weighted quantile L-estimators, such as traditional quantile estimators based on a linear combination of two order statistics, the Harrell–Davis quantile estimator and its trimmed modification. Our approach is based on a linear combination of multiple order statistics with linear coefficients obtained from the weights of the sample elements around the target quantile.
Content
- Preliminaries: review existing approaches to weighted quantile estimations, discuss their disadvantages, and propose a list of requirements for weighted quantile estimators that make them practically applicable for quantile exponential smoothing.
- Effective sample size: introduce the effective sample size for weighted estimators.
- Weighted Harrell–Davis quantile estimator, Weighted trimmed Harrell–Davis quantile estimator: build weighted versions of the Harrell–Davis quantile estimator and its trimmed modification.
- Weighted traditional quantile estimators: apply a similar approach to traditional quantile estimators based on a linear combination of two order statistics and build the corresponding weighted quantile estimators.
- Simulation studies: perform a series of simulation studies and show practical use cases of applying weighted quantile estimators.
- Summary: summarize all the results.
- Reference implementation: provide a reference R implementation of the described estimators.
Preliminaries
Let $\x = \{ x_1, x_2, \ldots, x_n \}$ be a sample of size $n$. We assign non-negative weight coefficients $w_i$ with a positive sum for all sample elements:
$$ \w = \{ w_1, w_2, \ldots, w_n \}, \quad w_i \geq 0, \quad \sum_{i=1}^{n} w_i > 0. $$For simplification, we also consider normalized (standardized) weights $\overline{\w}$:
$$ \overline{\w} = \{ \overline{w}_1, \overline{w}_2, \ldots, \overline{w}_n \}, \quad \overline{w}_i = \frac{w_i}{\sum_{i=1}^{n} w_i}. $$Let $x_{(i)}$ be the $i^\textrm{th}$ order statistic of $\x$, $w_{(i)}$ be the weight associated with $x_{(i)}$, and $\overline{w}_{(i)}$ be the corresponding normalized weight. We denote partial sums of $w_{(i)}$ and $\overline{w}_{(i)}$ by $s_i(\cdot)$:
$$ s_i(\w) = \sum_{j=1}^{i} w_{(j)}, \quad s_i(\overline{\w}) = \sum_{j=1}^{i} \overline{w}_{(j)}, \quad s_0(\w) = s_0(\overline{\w}) = 0. $$In the non-weighted case, we can consider a quantile estimator $\Q(\x, p)$ that estimates the $p^\textrm{th}$ quantile of the underlying distribution. We want to build a weighted quantile estimator $\Q^*(\x, \w, p)$ so that we can estimate the quantiles of a weighted sample. The problem of weighted quantile estimations arises in different contexts.
One of the possible applications is estimating the quantiles of a mixture distribution. Let us consider an example of building such a weighted estimator for a mixture of three distributions given by their cumulative distribution functions (CDFs) $F_X$, $F_Y$, and $F_Z$ with weights $w_X$, $w_Y$, and $w_Z$. The weighted mixture is given by $F=\overline{w}_X F_X + \overline{w}_Y F_Y + \overline{w}_Z F_Z$. Let us say that we have samples $\mathbf{x}$, $\mathbf{y}$, and $\mathbf{z}$ from $F_X$, $F_Y$, and $F_Z$; and we want to estimate the quantile function $F^{-1}$ of the mixture distribution $F$. If each sample contains a sufficient number of elements, we can consider a straightforward approach:
- Obtain empirical distribution quantile functions $\hat{F}^{-1}_X$, $\hat{F}^{-1}_Y$, $\hat{F}^{-1}_Z$ based on the given samples;
- Invert quantile functions and obtain estimations $\hat{F}_X$, $\hat{F}_Y$, $\hat{F}_Z$ of the CDFs for each distribution;
- Combine these CDFs and build an estimation $\hat{F}=\overline{w}_X\hat{F}_X+\overline{w}_Y\hat{F}_Y+\overline{w}_Z\hat{F}_Z$ of the mixture CDF;
- Invert $\hat{F}$ and get the estimation $\hat{F}^{-1}$ of the mixture distribution quantile function.
Unfortunately, this scheme performs poorly in the case of small sample sizes due to inaccurate estimations of the individual CDFs. Also, it is not extendable to the exponential smoothing problem.
Another approach that can be considered is the weighted kernel density estimation (KDE). It suggests estimating the probability density function (PDF) $f$ as follows:
$$ \hat{f}(x) = \sum_{i=1}^n \frac{\overline{w}_i}{h} K \left( \frac{x - x_i}{h} \right), $$where $K$ is the kernel (typically, the standard normal distribution is used), $h$ is the bandwidth. Next, we obtain the corresponding CDF by integrating the PDF and get the quantile function by inverting the CDF. This approach is applicable in some cases, but it inherits all the disadvantages of the non-weighted KDE. Firstly, it heavily depends on the choice of the kernel and the bandwidth. For example, Silverman’s and Scott’s rules of thumb for bandwidth selection (which are used by default in many statistical packages) perform poorly in the non-normal case and mask multimodality. Secondly, it extends the range of the quantile values: lower and higher quantiles exceed the minimum and maximum values of $\x$, which is not always acceptable. Still, there are some implementations of weighted KDE that use various bandwidth and kernel selectors (e.g., see wolters2018, wang2007, guillamon1998).
The proper choice of a weighted quantile estimator depends not only on the estimator properties, but also on the research goals. Different goals require different estimators. We already discussed the problem of estimating the quantiles of a mixture distribution based on individual samples. This paper primarily focuses on another problem called quantile exponential smoothing. Within this problem, we consider $\x$ as a time series of measurements. The goal is to estimate the distribution at the tail of this time series (the actual or latest state of the underlying system). The latest series element $x_n$ is the most actual one, but we cannot build a distribution based on a single element. Therefore, we have to take into account more elements at the end of $\x$. However, if we take too many elements, we may corrupt the estimations due to obsolete measurements.
Let us consider the problem of estimating distribution quantiles at the tail of a time series. One of the simplest approaches is to take the last $k$ measurements without weights and estimate quantiles based on the obtained data. This approach may lead to inaccurate estimations. Let us illustrate it using two timeline plots:
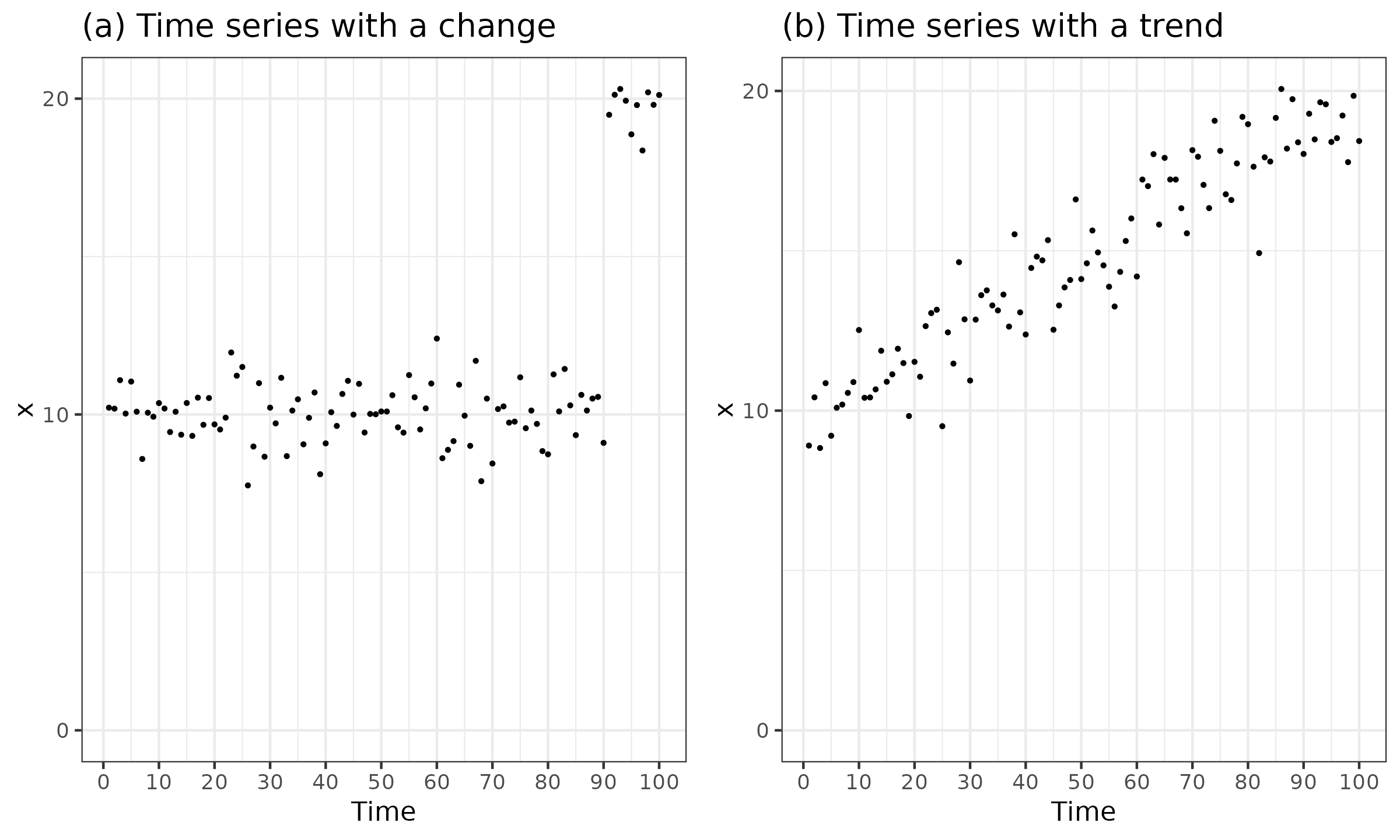
In Figure ?(a), we can see a change point after the first 90 measurements. If the number of considered measurements $k$ is greater than 10, the selected elements include “obsolete” values which corrupt the quantile estimations (especially lower quantiles). If $k$ is less than 10, we lose statistical efficiency due to an insufficiently large sample size. A possible solution for this problem is to automatically detect change points in the time series (an overview of change point detectors can be found in truong2020), and omit all the data before the last change point.
A drawback of this approach is presented in Figure ?(b). Here we can see a trend: the time series values are constantly increasing without any obvious change points. How should we choose the optimal value of $k$ in this situation? Small values of $k$ prevent us from having enough data, which is essential for accurate estimations. Large values of $k$ introduce too many obsolete values, contaminating the selected subsample and corrupting the estimations. Thus, we have a trade-off between the accuracy of estimations and resistance to obsolete measurements.
This trade-off is a severe issue in any approach that estimates the distribution at the tail of the time series using non-weighted subsamples formed from the last $k$ measurements. Adaptive strategies of choosing $k$ based on change point detectors slightly reduce the risk of obtaining invalid estimations, but they have smoothing issues when $x_{n-k}$ is around a change point.
The described problem can be mitigated using exponential smoothing. This approach assumes that we assign exponentially decreasing weights to the sample elements. That looks reasonable: the older the measurement, the lower its impact on the final estimations. The idea of exponential smoothing is widely used for the arithmetic mean (the corresponding approach is known as the exponentially weighted moving average). However, the mean is not robust: a single extreme outlier can corrupt the mean estimations. That is why it makes sense to switch to the quantiles, which allow us to describe the whole distribution even in the non-parametric heavy-tailed case. In order to apply exponential smoothing, we need weighted quantile estimators.
It is important to understand the difference between the problem of estimating mixture distribution quantiles and the smoothing problem. It is worth noting that this difference usually appears when the middle part of the estimated distribution contains low-density regions, which often arise due to multimodality. Such regions are always a source of trouble in quantile estimation since we typically do not have enough data for accurate estimations.
Let us consider the following distribution:
$$ F = \eps F_{\delta_{-1000}} + \frac{1-3\eps}{2} F_{\mathcal{U}(0,1)} + \eps F_{\delta_{10}} + \frac{1-3\eps}{2} F_{\mathcal{U}(99,100)} + \eps F_{\delta_{1000}}, $$where $F_{\star}$ is a CDF of the given distribution, $\delta_t$ is the Dirac delta distribution (it has all its mass at $t$), $\mathcal{U}(a, b)$ is a continuous uniform distribution on $[a;b]$, $\eps$ is a small positive constant. When we consider the problem of obtaining the true quantile values of the mixture distribution $F$, we should expect
$$ F^{-1}(0) = -1000,\quad F^{-1}(0.5) = 10,\quad F^{-1}(1) = 1000, $$which matches the true quantile values of $F$ for any positive $\eps$.
However, in the smoothing problem, we want to have a negligible impact of $F_{\delta_{-1000}}$, $F_{\delta_{10}}$, $F_{\delta_{1000}}$ on the quantile estimations when $\eps \to 0$. More specifically, we want to get
$$ F^{-1}(0) \approx 0,\quad F^{-1}(0.5) \approx 50,\quad F^{-1}(1) \approx 100. $$Although the expected values of $F^{-1}(p)$ are typically quite similar in both problems for most values of $p$, it is important to keep in mind the corner cases.
In this paper, we primarily focus on the problem of quantile exponential smoothing. To make the weighted quantile estimators practically useful, we define a list of desired properties that are expressed in the form of tree Requirements: R1, R2, R3.
Requirement R1: consistency with existing quantile estimators. There are multiple ways to estimate non-weighted quantiles. For example, we can consider the traditional quantile estimators based on linear interpolation of two order statistics (see hyndman1996), the Harrell–Davis quantile estimator (see harrell1982), and its trimmed modification (see akinshin2022thdqe). Different estimators have different characteristics in terms of statistical efficiency, computational efficiency, and robustness. Instead of creating a family of new weighted quantile estimators with different sets of properties, we want to build a generalization of the existing non-weighted estimators and inherit their properties. The generalized weighted estimator should be consistent with the original non-weighted estimator on the unit vector of weights $\w = \{ 1, 1, \ldots, 1 \}$:
$$ \Q^*(\x, \{ 1, 1, \ldots, 1 \}, p) = \Q(\x, p). $$Requirement R2: zero weight support. It is also reasonable to require that sample elements with zero weights should not affect the estimation:
$$ \Q^*(\{x_1, x_2, \ldots, x_{n-1}, x_n \}, \{w_1, w_2, \ldots, w_{n-1}, 0\}, p) = \Q^*(\{x_1, x_2, \ldots, x_{n-1} \}, \{w_1, w_2, \ldots, w_{n-1}\}, p). $$Requirement R3: stability. When we use exponential smoothing, we have to define the smoothing factor. This factor often requires some adjustments in order to achieve a balance between statistical efficiency and robustness. It is reasonable to expect that small changes in the smoothing factor should not produce significant changes in the obtained estimations. The continuity of the quantile estimations with respect to the weight coefficient makes the adjustment process more simple and controllable. Another essential use case is the addition of new elements, which leads to a slight reduction of weights of the existing elements. It is desirable that such a small reduction will not produce significant changes in the estimation. Generalizing, we require that minor changes in weight coefficients should not produce a major impact on the estimation. More formally,
$$ \lim_{\eps_i \to 0} \Q^*(\{x_1, x_2, \ldots, x_n \}, \{w_1 + \eps_1, w_2 + \eps_2, \ldots, w_n + \eps_n \}, p) \to \Q^*(\{x_1, x_2, \ldots, x_n \}, \{w_1, w_2, \ldots, w_n\}, p). $$This rule has a practically interesting use case of dropping elements with small weights. Indeed, it is reasonable to build a weighted sample for exponential smoothing based not on all available data but only on the last $k$ elements. With the exponential decay law, old elements get extremely small weights and therefore should not produce a noticeable impact on the estimation. In order to speed up the calculations, we should have an opportunity to exclude such elements from the sample:
$$ \begin{split} \lim_{\eps \to 0} & \Q^*(\{ x_1, x_2, \ldots, x_{n-1}, x_n \}, \{ \eps, w_2, \ldots, w_{n-1}, w_n \}) \stackrel{R3}{\to}\\ \stackrel{R3}{\to} & \Q^*(\{ x_1, x_2, \ldots, x_{n-1}, x_n \}, \{ 0, w_2, \ldots, w_{n-1}, w_n \}) \stackrel{R2}{=}\\ \stackrel{R2}{=} & \Q(\{ x_2, x_3, \ldots, x_n \}, \{ w_2, w_3, \ldots, w_n \}) \end{split} $$Now let us explore some of the existing solutions for the weighted quantile estimators in popular statistical packages. Most of these solutions are based on a single order statistic or a linear interpolation of two order statistics. Approaches based on a single order statistic violate R3: small fluctuations in $\w$ around the threshold point can “switch” the estimation from $x_{(i)}$ to $x_{(i-1)}$ or $x_{(i+1)}$. Approaches based on a linear interpolation of two subsequent order statistics also violate R3 as shown in the next example.
$\x = \{ 0, 1, 1, 100 \}$, $\w = \{ 1, \eps, \eps, 1 \}$, $p = 0.5$.
When $\eps=0$, $x_2$ and $x_3$ have zero weights and should be omitted, which gives us two equally weighted elements $\{ 0, 100 \}$. The traditional sample median of this sample is $50$. When $\eps>0$, the median estimation based on two subsequent order statistics should use $x_2$ and $x_3$ due to the symmetry of $\w$. Since $x_2=x_3=1$, the median estimation will be equal to $1$. Thus, the transition from $\eps=0$ to $\eps \to +0$ switches the median estimation from $50$ to $1$, which is a violation of R3.
Sometimes, approaches based on a linear interpolation of two non-subsequent order statistics are used in order to work around the problem from the above example. However, it is always possible to find examples that show violations of R3. Instead of analyzing all possible linear interpolation equations and discussing their disadvantages, we briefly provide examples of similar violations in popular weighted quantile estimator implementations. We limit our consideration scope to the R language since it is one of the most popular programming languages for statistical computing. Let us review the popular R implementation of weighted quantiles from the following CRAN packages: modi 0.1.0, laeken 0.5.2, MetricsWeighted 0.5.4, spatstat.geom 2.4-0, matrixStats 0.62.0, DescTools 0.99.46, Hmisc 4.7-1. Undesired behavior patterns are presented in the below examples.
$\x = \{ 0, 1, 100 \}$, $\w_A = \{ 1, 0, 1 \}$, $\w_B = \{ 1, 0.00001, 1 \}$, $p = 0.5$.
The only difference between $\w_A$ and $\w_B$ is in the second element: it changes from $0$ to $0.00001$.
Since the change is small, we can expect a small difference between $\Q(\x, \w_A, p)$ and $\Q(\x, \w_B, p)$.
Let us check the actual estimation values using modi, laeken, MetricsWeighted, spatstat.geom, matrixStats.
x <- c(0, 1, 100)
wA <- c(1, 0.00000, 1)
wB <- c(1, 0.00001, 1)
message(modi::weighted.quantile(x, wA, 0.5), " | ",
modi::weighted.quantile(x, wB, 0.5))
## 100 | 1
message(laeken::weightedQuantile(x, wA, 0.5), " | ",
laeken::weightedQuantile(x, wB, 0.5))
## 100 | 1
message(MetricsWeighted::weighted_quantile(x, wA, 0.5), " | ",
MetricsWeighted::weighted_quantile(x, wB, 0.5))
## 100 | 1
message(spatstat.geom::weighted.quantile(x, wA, 0.5), " | ",
spatstat.geom::weighted.quantile(x, wB, 0.5))
## 1 | 0.499999999994449
message(matrixStats::weightedMedian(x, wA), " | ",
matrixStats::weightedMedian(x, wB))
## 50 | 1.00000000000003
As we can see, all the considered packages have a discontinuity in quantile estimations around $w_2 = 0$. It is trivial to formally prove this fact for each particular implementation.
$\x = \{ 0, 1, 100 \}$, $\w_C = \{ 1, 0.99999, 1 \}$, $\w_D = \{ 1, 1, 1 \}$, $p = 0.5$.
This case is similar to the previous example, but now we change $w_2$ from $0.99999$ to $1$.
Let us review the actual estimation values using DescTools and Hmisc.
x <- c(0, 1, 100)
wC <- c(1, 0.99999, 1)
wD <- c(1, 1.00000, 1)
message(DescTools::Quantile(x, wC, 0.5), " | ",
DescTools::Quantile(x, wD, 0.5))
## 99.9995 | 1
message(Hmisc::wtd.quantile(x, wC, 0.5), " | ",
Hmisc::wtd.quantile(x, wD, 0.5))
## 99.9995 | 1
As we can see, these packages have a discontinuity around $w_2 = 1$. Moreover, the $\Q(\x, \w_C, p)$ estimations are counterintuitive. Indeed, since we expect $\Q^*(\{ 0, 1, 100 \}, \{ 1, 0, 1 \}, 0.5) = 50$ (R2) and $\Q^*(\{ 0, 1, 100 \}, \{ 1, 1, 1 \}, 0.5) = 1$ (R1), it is also reasonable to expect that $\Q^*(\{ 0, 1, 100 \}, \{ 1, 0.99999, 1 \}, 0.5) \in [1; 50]$. However, we observe a strange estimation value of 99.9995 for both packages.
Thus, we cannot rely on existing weighted quantile estimator implementations and we cannot reuse approaches for weighted mixture distribution. Therefore, we will build a new scheme for building weighted versions of some existing quantile estimators.
Effective sample size
All kinds of non-weighted quantile estimators explicitly or implicitly use the sample size. In order to satisfy Requirement R2, the sample size needs adjustments. Indeed, if we add another sample element with zero weight, we increment the actual sample size by one, which should not lead to changes in the estimations. To solve this problem, we suggest using Kish’s effective sample size (see kish1965) given by:
\begin{equation} n^*(\w) = \frac{\left( \sum_{i=1}^n w_i \right)^2}{\sum_{i=1}^n w_i^2 } = \frac{1}{\sum_{i=1}^n \overline{w}_i^2 }. \label{eq:kish} \end{equation}
To better understand Kish’s effective sample size, see Example ?.
Here are some examples of Kish’s effective sample size:
- $n^*(\{1, 1, 1\}) = 3$,
- $n^*(\{2, 2, 2\}) = 3$,
- $n^*(\{1, 1, 1, 0, 0\}) = 3$,
- $n^*(\{1, 1, 1, 0.00001\}) \approx 3.00002 $,
- $n^*(\{1, 2, 3, 4, 5\}) \approx 4.090909$.
We can also consider the Huggins–Roy family of effective sample sizes (proposed in huggins2019, advocated in elvira2022):
$$ \operatorname{ESS}_\beta(\overline{\mathbf{w}}) = \begin{cases} n - {\#}(\overline{w}_i = 0), & \textrm{if}\; \beta = 0, \\ \exp \left( -\sum_{i=1}^n \overline{w}_i \log \overline{w}_i \right), & \textrm{if}\; \beta = 1, \\ \frac{1}{\max[\overline{w}_1, \overline{w}_2, \ldots, \overline{w}_n]}, & \textrm{if}\; \beta = \infty, \\ \left( \frac{1}{\sum_{i=1}^n \overline{w}_i^\beta } \right)^{\frac{1}{\beta - 1}} = \left( \sum_{i=1}^n \overline{w}_i^\beta \right)^{\frac{1}{1 - \beta}}, & \textrm{otherwise}. \end{cases} $$All estimators in this family satisfy Requirement R2: additional zero weights do not affect the effective sample size value. It is also easy to see that Kish’s Equation \eqref{eq:kish} is a specific case of the Huggins–Roy family: $n^* = \operatorname{ESS}_2$. We continue building weighted quantile estimators using Kish’s approach, but other effective sample size estimators can be considered as well.
Weighted Harrell–Davis quantile estimator
The Harrell–Davis quantile estimator (see harrell1982) evaluates quantiles as a linear combination of all order statistics. Although this approach is not robust (its breakdown point is zero), it provides higher statistical efficiency in the cases of light-tailed distributions, which makes it a practically reasonable option under lighttailedness. We start with this particular estimator instead of the traditional approaches because it has an intuition-friendly weighted case generalization.
The classic non-weighted Harrell–Davis quantile estimator is given by:
\begin{equation} \QHD(\x, p) = \sum_{i=1}^{n} W_{\operatorname{HD},i} \cdot x_{(i)},\quad W_{\operatorname{HD},i} = I_{t_i}(\alpha, \beta) - I_{t_{i-1}}(\alpha, \beta), \label{eq:hd} \end{equation}
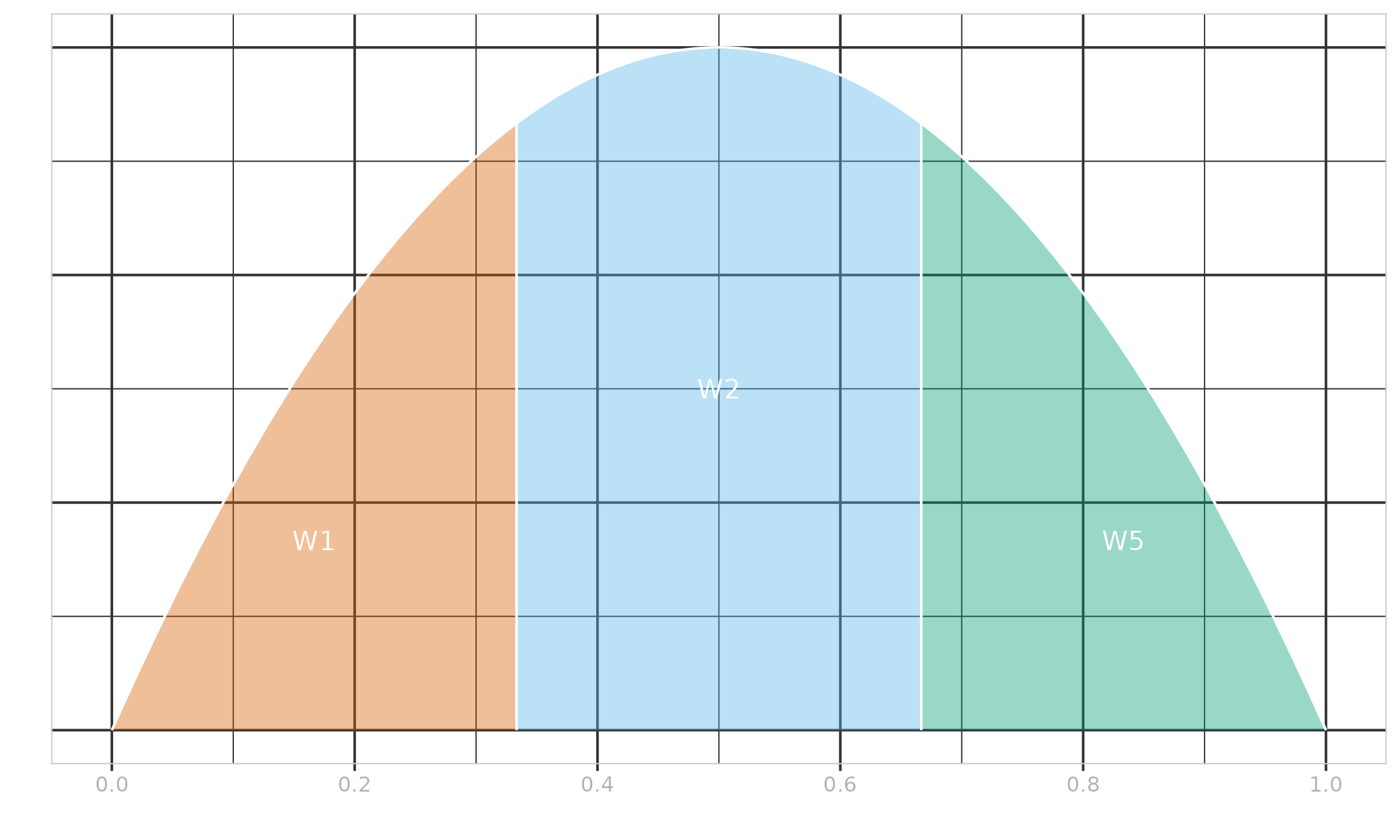
where $I_t(\alpha, \beta)$ is the regularized incomplete beta function, $t_i = i/n$, $\alpha = (n+1)p$, $\;\beta = (n+1)(1-p)$. See Example ? to get the intuition behind the Harrell–Davis quantile estimator.
$\x = \{ 1, 2, 4, 8, 16 \}$, $p = 0.5$.
We estimate the median for a sample of size $5$,
which gives us $\alpha = \beta = 3$.
Let us consider the PDF of the beta distribution
$\Beta(3, 3)$ presented in Figure ?.
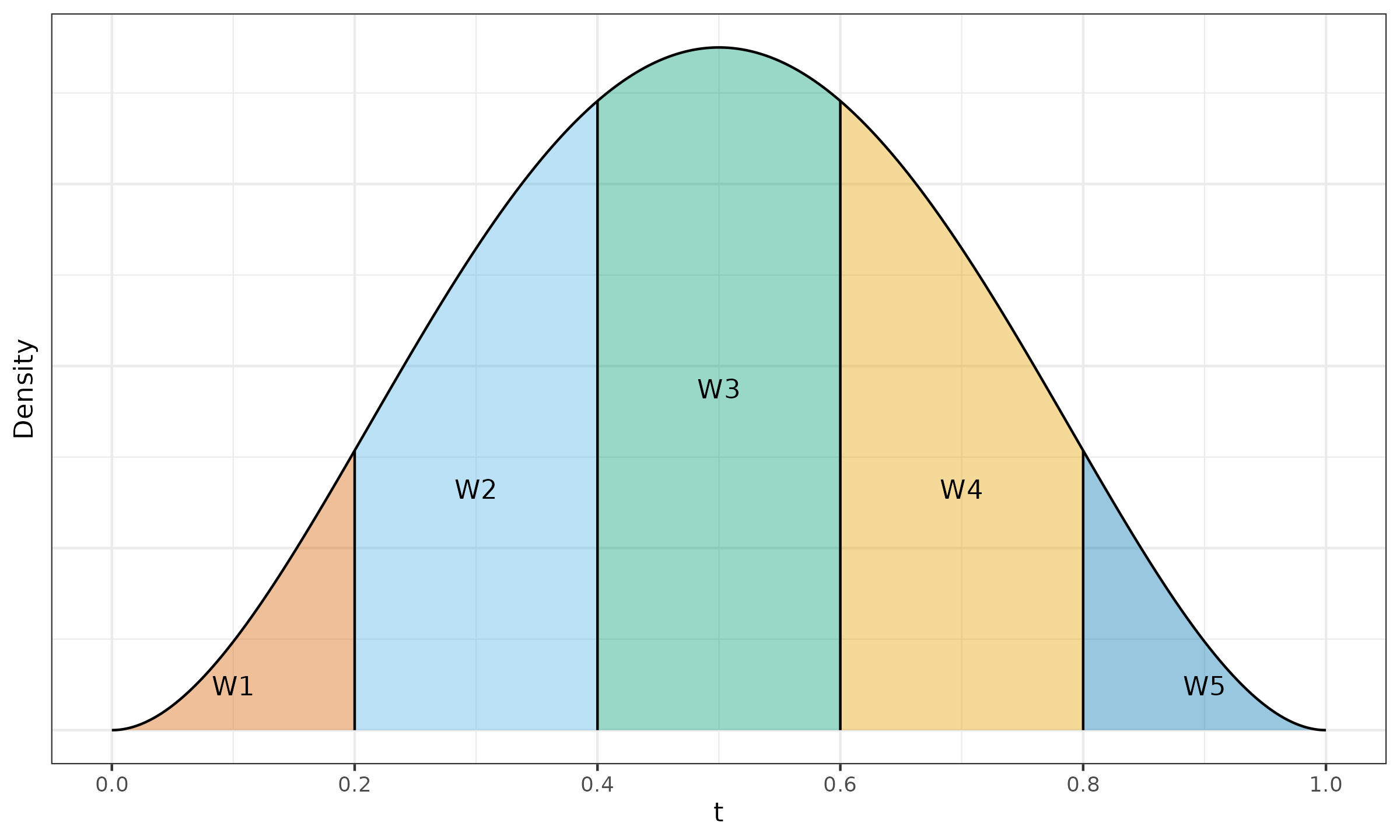
This PDF is split into five fragments with cut points given by
$$ t_{\{ 0..5\}} = \{ t_0, t_1, t_2, t_3, t_4, t_5 \} = \{ 0, 0.2, 0.4, 0.6, 0.8, 1 \}. $$Since $I_t(\alpha, \beta)$ is the CDF of the beta distribution $\Beta(\alpha, \beta)$, the area of the $i^\textrm{th}$ fragment is exactly $I_{t_i}(\alpha, \beta) - I_{t_{i-1}}(\alpha, \beta) = W_{\operatorname{HD},i}$. Here are the corresponding linear coefficient values:
$$ W_{\operatorname{HD},\{1..5\}} \approx \{ 0.058, 0.26, 0.365, 0.26, 0.058 \}. $$Now we can calculate the Harrell–Davis median estimation:
$$ \QHD(\x, p) = \sum_{i=1}^{n} W_{\operatorname{HD},i} \cdot x_{(i)} \approx 5.04. $$We can interpret the $W_{\operatorname{HD},i}$ coefficients as probabilities of observing the target quantile at the given position. Thus, the Harrell–Davis estimation is a weighted sum of all order statistics according to these probabilities.
In the non-weighted case, all segments $[t_{i-1}; t_i]$ have the same width of $1/n$. For the weighted case, we suggest replacing them with intervals $[t^*_{i-1}; t^*_i]$ that have widths proportional to the element weights $w_{(i)}$. Thus, we can define $t^*_i$ via partial sums of normalized weight coefficients:
$$ \begin{equation} t^*_i = s_i(\overline{\w}). \label{eq:whd-t} \end{equation} $$Since we use Kish’s effective sample size $n^*$ in the weighted case, the values of $\alpha$ and $\beta$ should be also properly adjusted:
$$ \begin{equation} \alpha^* = (n^* + 1) p, \quad \beta^* = (n^* + 1) (1 - p). \label{eq:whd-ab} \end{equation} $$Using Equation \eqref{eq:whd-t} and Equation \eqref{eq:whd-ab}, we can define the weighted Harrell–Davis quantile estimator:
$$ \begin{equation} \QHD^*(\x, \w, p) = \sum_{i=1}^{n} W^*_{\HD,i} \cdot x_{(i)},\quad W^*_{\HD,i} = I_{t^*_i}(\alpha^*, \beta^*) - I_{t^*_{i-1}}(\alpha^*, \beta^*). \label{eq:whd} \end{equation} $$The only corner cases for the Harrell–Davis quantile estimator are $p=0$ and $p=1$ since $\Beta(\alpha, \beta)$ is defined only when $\alpha, \beta > 0$. For all $p \in (0;1)$, $\QHD^*(\x, \w, p)$ satisfies all of the declared requirements.
The usage of $\QHD^*(\x, \w, p)$ is demonstrated in Example ? and Example ?.
$\x = \{ 1, 2, 3, 4, 5 \}$, $\w = \{ 1, 1, 0, 0, 1 \}$, $p = 0.5$.
Without the given weights $\w$, the linear coefficients $W_{\HD,i}$ are defined as shown in Example ?. When we consider the weighted case, $x_{(3)}$ and $x_{(4)}$ should be automatically omitted because $w_{(3)}=w_{(4)}=0$. From Equation \eqref{eq:kish} and Equation \eqref{eq:whd-ab}, we get $n^* = 3,\, \alpha^* = \beta^* = 2$, which gives us $\Beta(2, 2)$ (the PDF is shown in Figure ?). The cut points are given by:
$$ t^*_{\{0..5\}} = \{ 0,\; 1/3,\; 2/3,\; 2/3,\; 2/3,\; 1 \}. $$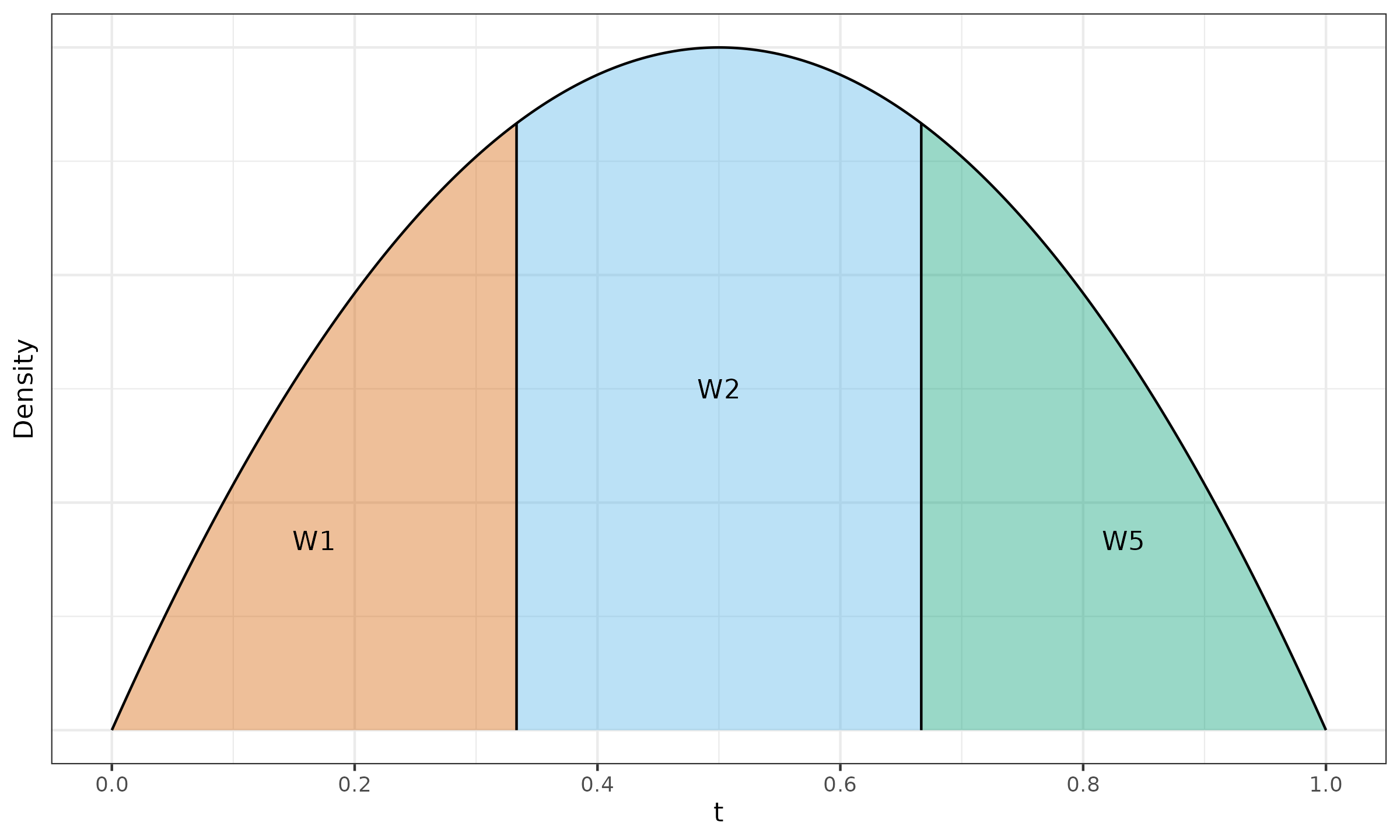
Using $I_t(2, 2)$, we can obtain the Harrell–Davis linear coefficients:
$$ W^*_{\operatorname{HD},\{1..5\}} \approx \{ 0.259, 0.481, 0, 0, 0.259 \}. $$Thus, elements $x_{(3)}$ and $x_{(4)}$ are indeed automatically eliminated. The median is estimated as in the non-weighted case for three elements:
$$ \QHD^*(\{ 1, 2, 3, 4, 5 \}, \{ 1, 0, 0, 1, 1 \}, 0.5) = \QHD(\{ 1, 2, 5 \}, 0.5) \approx 2.518519. $$$\x = \{ 1, 2, 3, 4, 5 \}$, $\w = \{ 0.4, 0.4, 0.05, 0.05, 0.1 \}$, $p = 0.5$.
From Equation \eqref{eq:kish} and Equation \eqref{eq:whd-ab}, we get
which gives us $\Beta(1.993, 1.993)$ (the PDF is shown in Figure ?). The cut points are given by:
$$ t^*_{\{0..5\}} = \{ 0, 0.4, 0.8, 0.85, 0.9, 1 \}. $$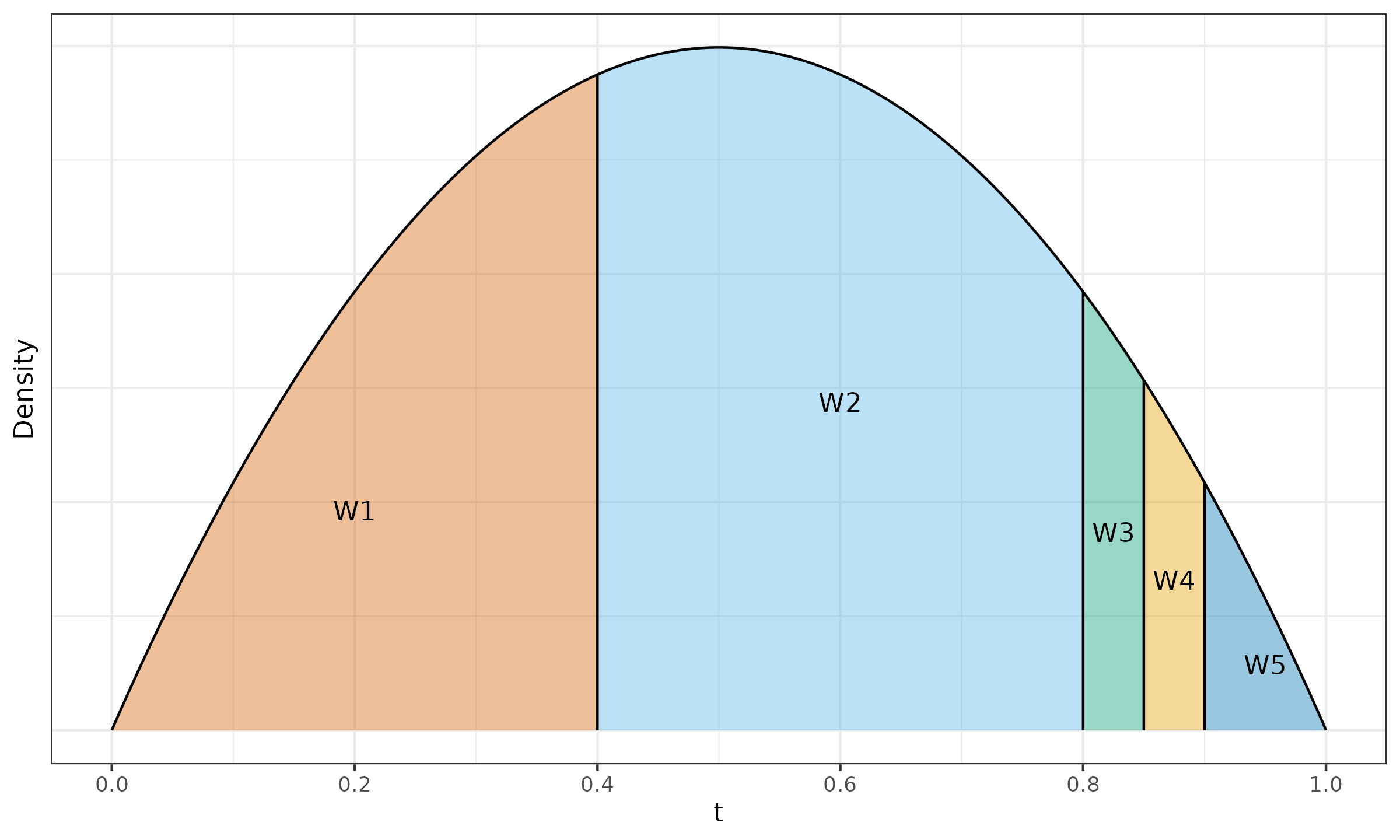
Using $I_t(1.993, 1.993)$, we can obtain the Harrell–Davis linear coefficients:
$$ W^*_{\operatorname{HD},\{1..5\}} \approx \{ 0.352, 0.543, 0.043, 0.033, 0.028 \}. $$Even though we estimate the median, $x_{(2)}$ has the highest linear coefficient $W^*_{\operatorname{HD},2} \approx \{ 0.543 \}$ due to the high value of $w_{(2)} = 0.4$. The second highest linear coefficient $W^*_{\operatorname{HD},1} \approx \{ 0.352 \}$ corresponds to the first order statistic $x_{(1)}$; it is smaller than $W^*_{\operatorname{HD},2}$ because it is farther from the center than $x_{(2)}$, but it is larger than $W^*_{\operatorname{HD},3}$ because the interval $[t^*_0; t^*_1] = [0;0.4]$ is larger and closer to the center than $[t^*_2; t^*_3] = [0.8;0.85]$.
Now we can estimate the median using the linear combination of all order statistics:
$$ \QHD^*(\x, \w, p) = \sum_{i=1}^{n} W^*_{\operatorname{HD},i} \cdot x_{(i)} \approx 1.842. $$Weighted trimmed Harrell–Davis quantile estimator
The Harrell–Davis quantile estimator is an efficient replacement for traditional quantile estimators due to its high statistical efficiency (especially for middle quantiles). However, this estimator is not robust: its breakdown point is zero. That is why we consider its trimmed modification (see akinshin2022thdqe). The basic idea is simple: since most of the linear coefficients $W_{\operatorname{HD},i}$ are pretty small, they do not have a noticeable impact on efficiency, but they significantly reduce the breakdown point. In akinshin2022thdqe, it was suggested to build a trimmed modification based on the beta distribution highest density interval $[L;R]$ of the given size $D$:
$$ \QTHD(\x, p) = \sum_{i=1}^{n} W_{\THD,i} \cdot x_{(i)}, \quad W_{\THD,i} = F_{\THD}(t_i) - F_{\THD}(t_{i-1}),\quad t_i = i / n, $$$$ F_{\THD}(t) = \begin{cases} 0 & \textrm{for }\, t < L,\\ \Bigl( I_t(\alpha, \beta) - I_L(\alpha, \beta) \Bigr) / \Bigl( I_R(\alpha, \beta) - I_L(\alpha, \beta) \Bigr) & \textrm{for }\, L \leq t \leq R,\\ 1 & \textrm{for }\, R < t. \end{cases} $$In the weighted case, we should replace the interval $[L;R]$ with the highest density interval of $\Beta(\alpha^*, \beta^*)$, which we denote by $[L^*;R^*]$. Adoption of Equation \eqref{eq:whd} for the trimmed Harrell–Davis quantile estimator is trivial:
$$ \begin{equation} \QTHD^*(\x, \w, p) = \sum_{i=1}^{n} W^*_{\operatorname{THD},i} \cdot x_{(i)}, \quad W^*_{\operatorname{THD},i} = F^*_{\operatorname{THD}}(t^*_i) - F^*_{\operatorname{THD}}(t^*_{i-1}),\quad t^*_i = s_i(\overline{\w}), \label{eq:wthd} \end{equation} $$$$ F^*_{\operatorname{THD}}(t) = \begin{cases} 0 & \textrm{for }\, t < L^*,\\ \Bigl( I_t(\alpha^*, \beta^*) - I_{L^*}(\alpha^*, \beta^*) \Bigr) / \Bigl( I_{R^*}(\alpha^*, \beta^*) - I_{L^*}(\alpha^*, \beta^*) \Bigr) & \textrm{for }\, L^* \leq t \leq R^*,\\ 1 & \textrm{for }\, R^* < t. \end{cases} $$Statistical efficiency and robustness of $\QTHD$ are explored in akinshin2022thdqe (Section “Simulation studies”).
Note that the trimmed Harrell–Davis quantile estimator has the same limitations as the original estimator: it is defined only for $p \in (0;1)$.
The difference between the original Harrell–Davis quantile estimator $\QHD$ and its trimmed modification $\QTHD$ is shown in Example ?.
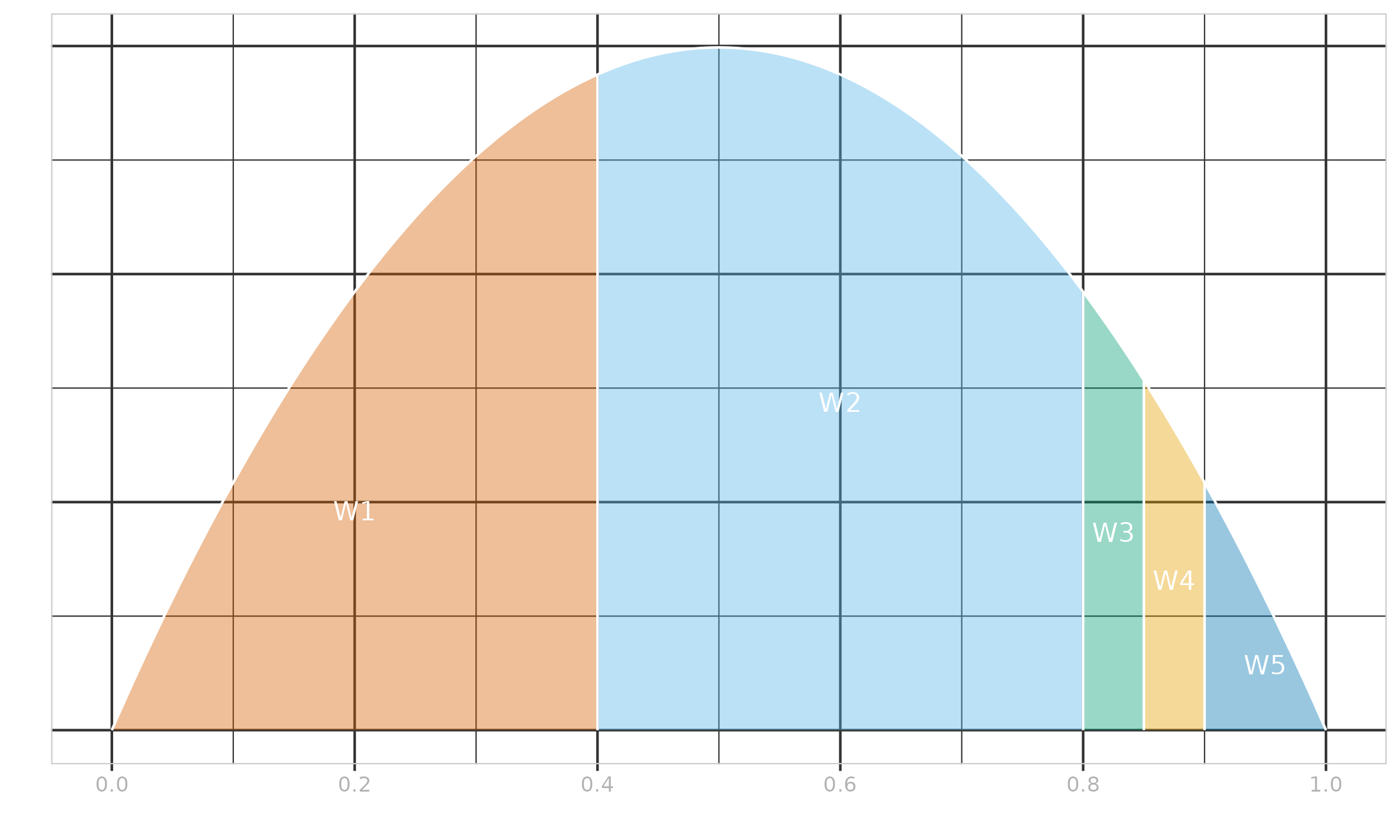
$\x = \{ 1, 2, 3, 10000 \}$, $\w = \{ 0.1, 0.4, 0.4, 0.1 \}$, $p = 0.5$.
From Equation \eqref{eq:kish} and Equation \eqref{eq:whd-ab}, we get $n^* \approx 2.941$, $\alpha^* = \beta^* \approx 1.971$, which gives us $\Beta(1.971, 1.971)$ (the PDF is shown in Figure ?). The cut points are given by:
$$ t^*_{\{0..4\}} = \{ 0, 0.1, 0.5, 0.9, 1 \}. $$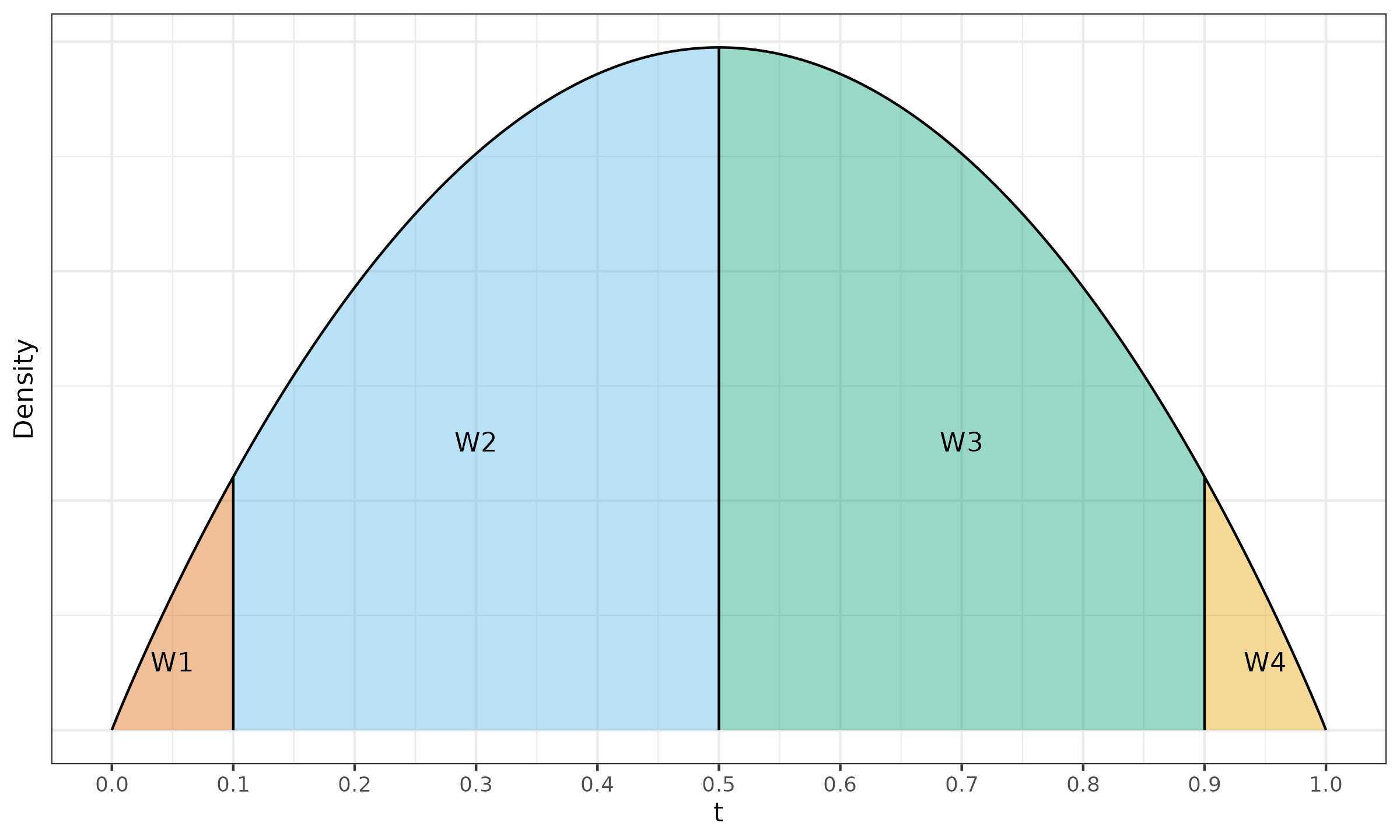
Using $I_t(1.971, 1.971)$, we can obtain the linear coefficients for the classic weighted Harrell–Davis quantile estimator:
$$ W^*_{\HD,\{1..4\}} \approx \{ 0.029, 0.471, 0.471, 0.029 \}. $$To define $Q_{\THD}$, we use the rule of thumb from akinshin2022thdqe and set $D^* = 1 / \sqrt{n^*} \approx 0.583$. Since $\w$ is symmetric, we get $[L^*;R^*] \approx [0.208, 0.792]$. It does not cover $[t^*_0;t^*_1]$ and $[t^*_3;t^*_4]$, therefore $W^*_{\THD,1} = W^*_{\THD,4} = 0$. The exact values of the linear coefficients $W^*_{\THD,i}$ are easy to obtain:
$$ W^*_{\THD,\{1..4\}} = \{ 0, 0.5, 0.5, 0 \}. $$Now we can estimate the median using both estimators:
$$ \QHD^*(\x, \w, p) = \sum_{i=1}^{n} W^*_{\operatorname{HD},i} \cdot x_{(i)} \approx 292.594,\quad \QTHD^*(\x, \w, p) = \sum_{i=1}^{n} W^*_{\operatorname{THD},i} \cdot x_{(i)} = 2.5. $$As we can see, the Harrell–Davis median estimation $\QHD^*(\x, \w, p) \approx 292.594$ is heavily affected by $x_{(4)} = 10000$ regardless of its small weight $w_{(4)} = 0.1$. The trimmed version of this estimator does not have such a problem thanks to a higher breakdown point: $\QTHD^*(\x, \w, p) = 2.5$.
Weighted traditional quantile estimators
Traditionally, statistical packages use various quantile estimation approaches, that are based on one or two order statistics. We use the Hyndman–Fan quantile estimator taxonomy (see hyndman1996), which is presented in Table ?. Here $\lfloor\cdot\rfloor$ and $\lceil\cdot\rceil$ are the floor and ceiling functions; $\lfloor\cdot\rceil$ is the banker’s rounding (if the number falls midway between two integers, it is rounded to the nearest even value). If the obtained $h$ value is less than $1$ or larger than $n$, it should be clamped to the $[1;n]$ interval.
| Type | h | Equation |
|---|---|---|
| 1 | $np$ | $x_{(\hc)}$ |
| 2 | $np+1/2$ | $(x_{(\lceil h - 1/2 \rceil)} + x_{(\lceil h + 1/2 \rceil)})/2$ |
| 3 | $np$ | $x_{(\hr)}$ |
| 4 | $np$ | $x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)})$ |
| 5 | $np+1/2$ | $x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)})$ |
| 6 | $(n+1)p$ | $x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)})$ |
| 7 | $(n-1)p+1$ | $x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)})$ |
| 8 | $(n+1/3)p+1/3$ | $x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)})$ |
| 9 | $(n+1/4)p+3/8$ | $x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)})$ |
In this classification, only Types 4–9 are continuous; Types 1–3 have discontinuities, so the corresponding estimators fail to satisfy Requirement R3. Therefore, we consider only Types 4–9 in the rest of the paper (the most popular default option is Type 7). These estimators use the same interpolation equation:
$$ \begin{equation} \Q_k(\x, p) = x_{(\hf)}+(h-\hf)(x_{(\hc)} - x_{(\hf)}), \label{eq:hf1} \end{equation} $$where $k$ is the index of the quantile estimator in the Hyndman–Fan taxonomy, $h$ is defined in Table ? according to the given $k$.
We try to adopt the weighted approach proposed in Sections Weighted Harrell–Davis quantile estimator and Weighted trimmed Harrell–Davis quantile estimator for $\QHD$ and $\QTHD$. In order to do it, we should express the original non-weighted estimators in a way similar to the Harrell–Davis quantile estimator. However, instead of the Beta distribution, we should define another one that assigns linear coefficients to order statistics. Since $\Q_k$ always uses a linear combination of two order statistics, the most straightforward approach is to use the uniform distribution $\mathcal{U}\bigl((h-1)/n, h/n\bigr)$, which is defined by the following PDF $f_k$ and CDF $F_k$:
$$ f_k(t) = \left\{ \begin{array}{lcrcllr} 0 & \textrm{for} & & & t & < & (h-1)/n, \\ n & \textrm{for} & (h-1)/n & \leq & t & \leq & h/n, \\ 0 & \textrm{for} & h/n & < & t, & & \end{array} \right. $$$$ F_k(t) = \left\{ \begin{array}{lcrcllr} 0 & \textrm{for} & & & t & < & (h-1)/n, \\ tn-h+1 & \textrm{for} & (h-1)/n & \leq & t & \leq & h/n, \\ 1 & \textrm{for} & h/n & < & t. & & \end{array} \right. $$Now Equation \eqref{eq:hf1} can be rewritten in a form that matches the definition of $\QHD$ (Equation \eqref{eq:hd}):
$$ \begin{equation} Q_k(\x, p) = \sum_{i=1}^{n} W_{F_k,i} \cdot x_{(i)},\quad W_{F_k, i} = F_k(t_i) - F_k(t_{i-1}),\quad t_i = i / n. \label{eq:hf2} \end{equation} $$Illustrations of Equation \eqref{eq:hf2} for $Q_7$ are given in Example ? and Example ?.
$n = 5$, $p = 0.25$.
We have integer $h = 2$, which gives us the PDF and CDF presented in Figure ?.
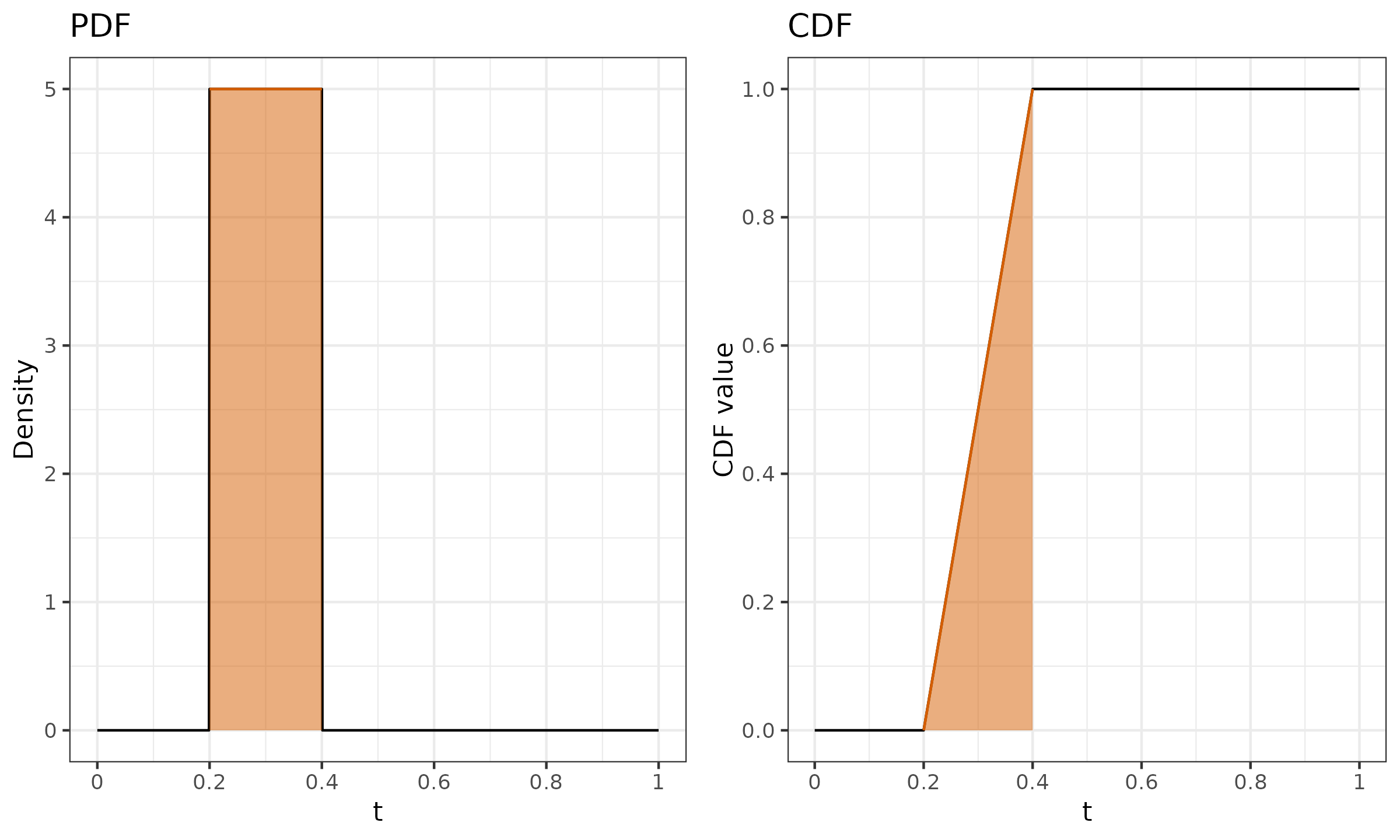
It is easy to see that we have only one non-negative $W_{F_7,i}$: $W_{F_7,2} = 1$. This means that $Q_7(\{ x_1, x_2, x_3, x_4, x_5 \}, 0.25) = x_{(2)}$, which satisfies our expectations (the first quartile of a sample with five elements is the second element).
$n = 5$, $p = 0.35$.
We have non-integer $h = 2.4$, which gives us the PDF and CDF presented in Figure ?.
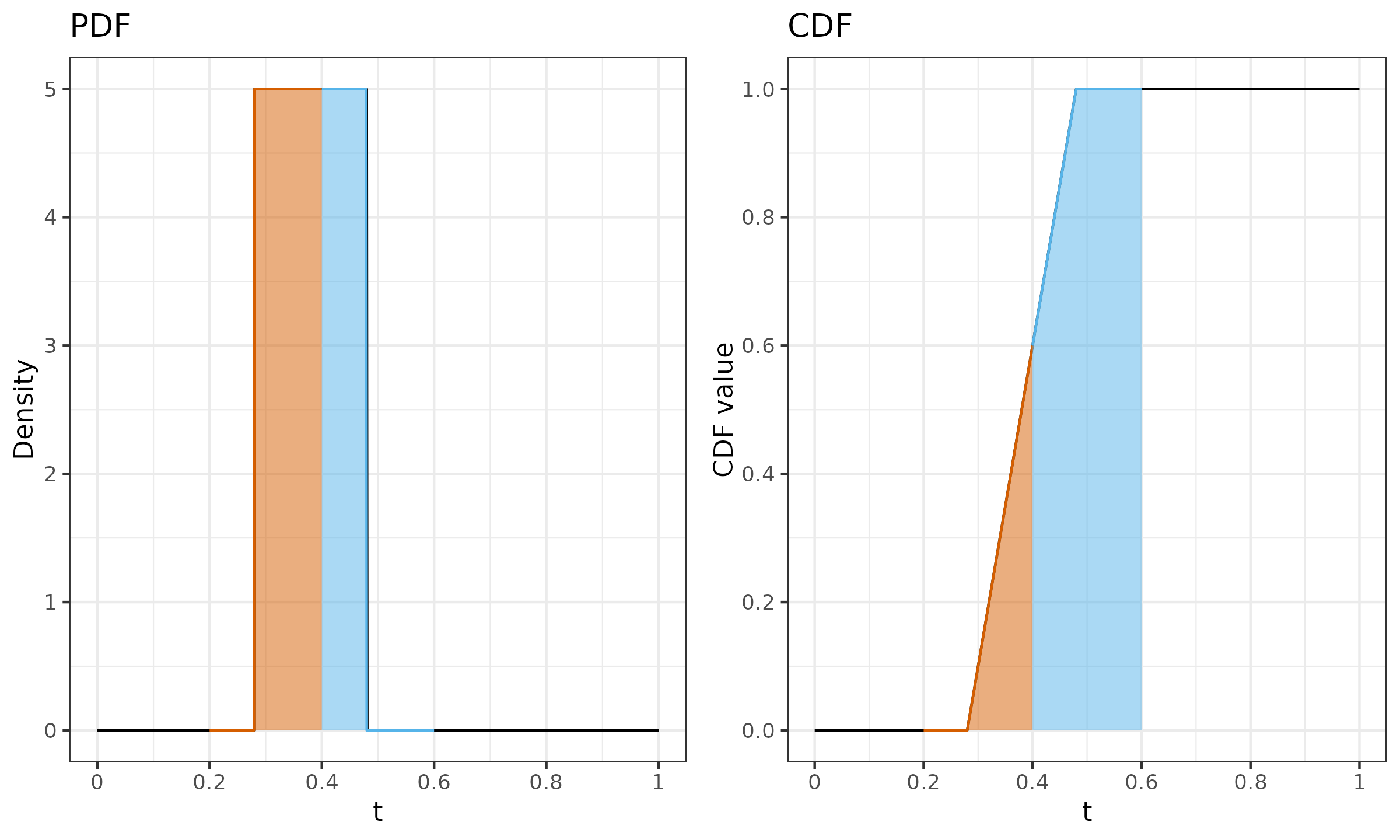
As we can see, the $0.35^\textrm{th}$ quantile estimation is a linear combination of $x_{(2)}$ and $x_{(3)}$ with coefficients $W_{F_7, 2} = 0.6$, $W_{F_7, 3} = 0.4$. Thus, $Q_7(\{ x_1, x_2, x_3, x_4, x_5 \}, 0.35) = 0.6 \cdot x_{(2)} + 0.4 \cdot x_{(3)}$.
As we can see, the suggested $F_k$ perfectly matches the non-weighted case. Now we can generalize Equation \eqref{eq:hf2} to the weighted case similarly to Equation \eqref{eq:whd} and Equation \eqref{eq:wthd} (assuming $h^*$ is obtained from Table ? based on $n^*$):
$$ Q_k^*(\x, \w, p) = \sum_{i=1}^{n} W^*_{F^*_k,i} \cdot x_{(i)},\quad W^*_{F^*_k, i} = F^*_k(t^*_i) - F^*_k(t^*_{i-1}),\quad t^*_i = s_i(\overline{\w}), $$$$ F^*_k(t) = \left\{ \begin{array}{lcrcllr} 0 & \textrm{for} & & & t & < & (h^*-1)/n^*, \\ tn^*-h^*+1 & \textrm{for} & (h^*-1)/n^* & \leq & t & \leq & h^*/n^*, \\ 1 & \textrm{for} & h^*/n^* & < & t. & & \end{array} \right. $$The usage of $Q_7^*(\x, \w, p)$ is shown in Example ?. More examples can be found in Section Simulation studies.
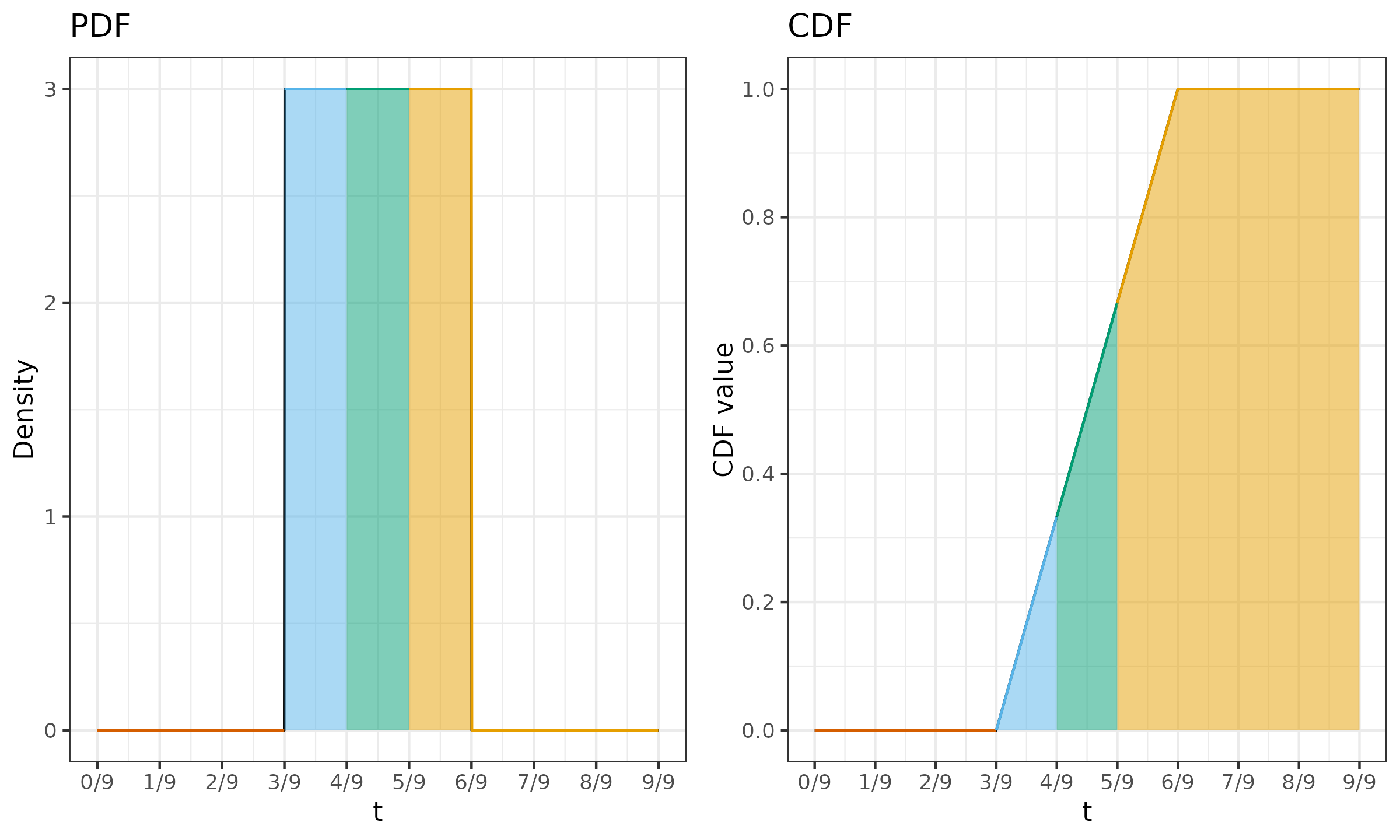
${\x = \{ 1, 2, 3, 4, 5\},\, \w = \{ 0.3, 0.1, 0, 0.1, 0.4 \},\, p = 0.5}$.
In this case, $n^* = 3$, $h^* = (n^*-1)p + 1 = 2$, which gives us the following expression for $F^*_7$:
Now we can calculate the values of the intermediate variables:
$$ \begin{aligned} \overline{\w} & = \{ 3/9,\; 1/9,\; 0,\; 1/9,\; 4/9 \},\\ t^*_{\{0..5\}} & = \{ 0,\; 3/9,\; 4/9,\; 4/9,\; 5/9,\; 1 \},\\ F^*_7(t^*_{\{0..5\}}) & = \{ 0,\; 0,\; 1/3,\; 1/3,\; 2/3,\; 1 \},\\ W^*_{F^*_7, \{1..5\}} & = \{ 0,\; 1/3,\; 0,\; 1/3,\; 1/3 \}. \end{aligned} $$Finally, the median estimation is defined as follows:
$$ Q_7^*(\x, \w, p) = \sum_{i=1}^n W^*_{F^*_7, i} \cdot x_{(i)} = (x_{(2)} + x_{(4)} + x_{(5)}) / 3 = 11/3 \approx 3.666667. $$This example is illustrated in Figure ?.
Simulation studies
In this section, we perform several simulation studies in order to show the practical usage examples of the suggested approach in various contexts. These simulations are not comprehensive research of the estimator properties but rather just illustrations demonstrating practical applications of the weighted quantile estimators.
Simulation 1: Median exponential smoothing
In this study, we discuss the problem of quantile exponential smoothing and consider $\x$ as a time series of some measurements (the oldest measurements are at the beginning of the series, and the newest measurements are at the end). In such situations, it is convenient to assign weights according to the exponential decay law:
$$ \begin{equation} \omega(t) = 2^{-t/t_{1/2}}, \label{eq:decay-exp} \end{equation} $$where the parameter $t_{1/2}$ is known as the half-life. This value describes the period required for the current weight to reduce to half of its original value. Thus, we have
$$ \omega(0) = 1, \quad \omega(t_{1/2}) = 0.5, \quad \omega(2t_{1/2}) = 0.25, \quad \omega(3t_{1/2}) = 0.125, \quad \ldots $$The simplest way to define $\w$ for our time series is to apply the exponential decay law in a reverse way:
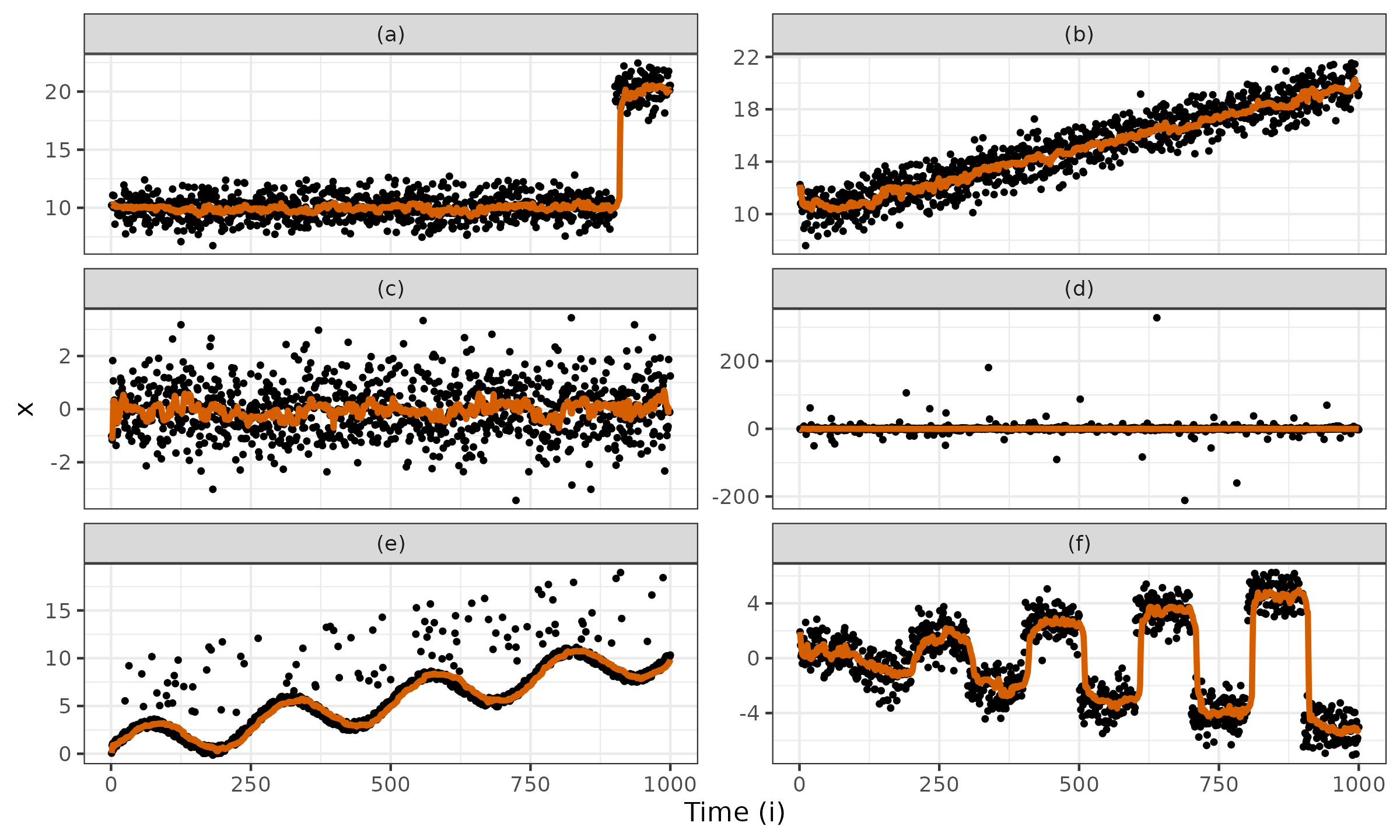
$$ \begin{equation} w_i = \omega(n - i). \label{eq:decay-rev} \end{equation} $$An example of the median exponential smoothing for various time series is presented in Figure ? ($n = 1\,000$, $t_{1/2}=10$, the weights are assigned according to Equation \eqref{eq:decay-rev}). The following time series are considered:
- (a) Two normal distributions split by a change point: $x_i \in \mathcal{N}(10, 1)$ for $1 \leq i \leq 900$; $x_i \in \mathcal{N}(20, 1)$ for $901 \leq i \leq 1\,000$;
- (b) A moving normal distribution: $x_i \in \mathcal{N}(10 + i / 100, 1)$;
- (c) The standard normal distribution: $x_i \in \mathcal{N}(0, 1)$;
- (d) The standard Cauchy distribution: $x_i \in \operatorname{Cauchy}(0, 1)$;
- (e) A monotonically increasing sine wave pattern with occasional outliers;
- (f) “Dispersing” normal distributions: $x_i \in \mathcal{N}\Bigl(\bigl( 2\cdot (j \bmod 2) - 1 \bigr) \cdot \bigl(j / 2 + ((i - 1) \bmod 100) / 100 \bigr) , 1\Bigr)$, where $j = \lfloor (i - 1) / 100 \rfloor + 1$.
For each time series, we consider all the subseries that start at the beginning: $\{ x_1, x_2, \ldots, x_i\}$. For each subseries, we estimate the median using $Q_7^*$. Thus, we get the moving (running) median shown in Figure ? with a bold line. As we can see, the obtained estimations match our expectations: the moving median follows the trends and quickly recovers after change points.
In practical applications, more sophisticated weight assignation strategies can be used. For example, if we collect a group of measurements daily, and we know that each group is obtained from the same distribution (no changes can be introduced between measurements within the same group), the exponential law can be applied on a per-group basis (all the group elements get the same weight).
Simulation 2: Quartile exponential smoothing
In this simulation, we consider a time series consisting of four parts:
- $(S_1)\; i \in \{ \phantom{00}1..100 \}:\; x_i \in \mathcal{N}(0, 1)$;
- $(S_2)\; i \in \{ 101..200 \}:\; x_i \in \mathcal{N}(10, 1)$;
- $(S_3)\; i \in \{ 201..300 \}:\; x_i \in \mathcal{N}(0, 1)$;
- $(S_4)\; i \in \{ 301..500 \}:\; x_i \in 0.4\cdot\mathcal{N}(-10, 1) + 0.2\cdot\mathcal{N}(0, 1) + 0.4\cdot\mathcal{N}(10, 1)$.
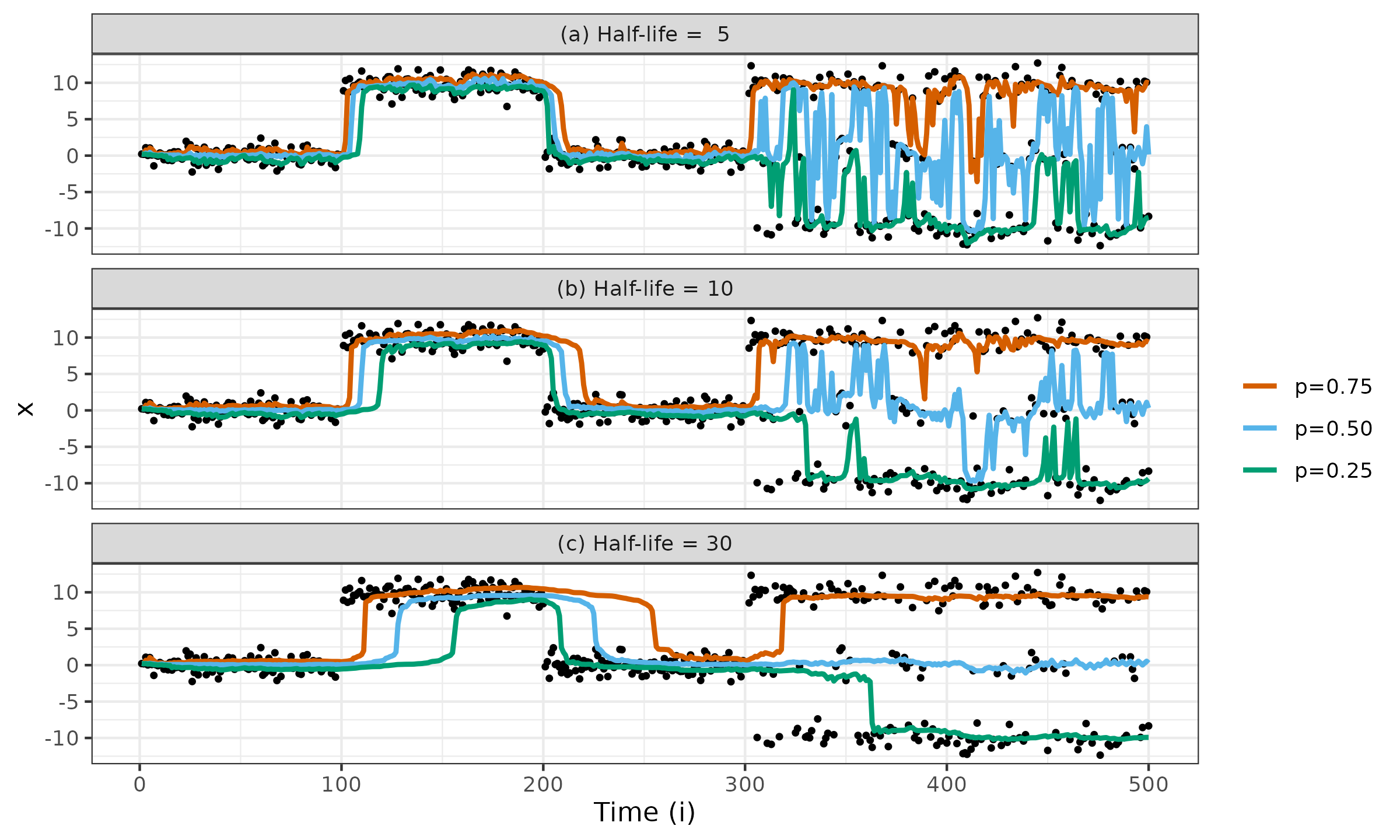
Similar to the previous simulation, we calculate running estimations. In addition to the running median (which is also the second quartile and the $50^\textrm{th}$ percentile), we consider the first and the third running quartiles (which are also the $25^\textrm{th}$ and $75^\textrm{th}$ percentiles respectively). The weights $w_i$ are assigned according to the exponential law defined in Equation \eqref{eq:decay-exp} and Equation \eqref{eq:decay-rev}. We enumerate three half-life values: (a) $t_{1/2}=5$, (b) $t_{1/2}=10$, (c) $t_{1/2}=30$.
The simulation results are presented in Figure ?. Based on these plots, we can make the following observations:
- In the context of quantile exponential smoothing, the running median is the most reliable metric: it quickly adapts to various distribution changes.
- Higher and lower running quantiles perform worse: the adaptation period to the distribution changes heavily depends on the direction of these changes.
- Small half-life values shorten the adaptation period but increase the dispersion of estimations. Large half-life values enlarge the adaptation period but decrease the dispersion of estimations. If the target quantile is around a low-density region, it needs a larger half-life value to avoid jumping between neighboring high-density regions.
Simulation 3: Weighted mixture distribution
As we have discussed in Section Preliminaries, the problems of quantile exponential smoothing and the weighted mixture distribution quantile estimation may have different expectations of the quantile values (see Example ?). However, the issues typically arise when we estimate a single quantile value in a low-density region. If we are estimating all values of the quantile function or if we are interested in quantile values in high-density regions, the described weighted quantile estimators usually produce reliable results. Let us conduct one more simulation study to illustrate these cases.
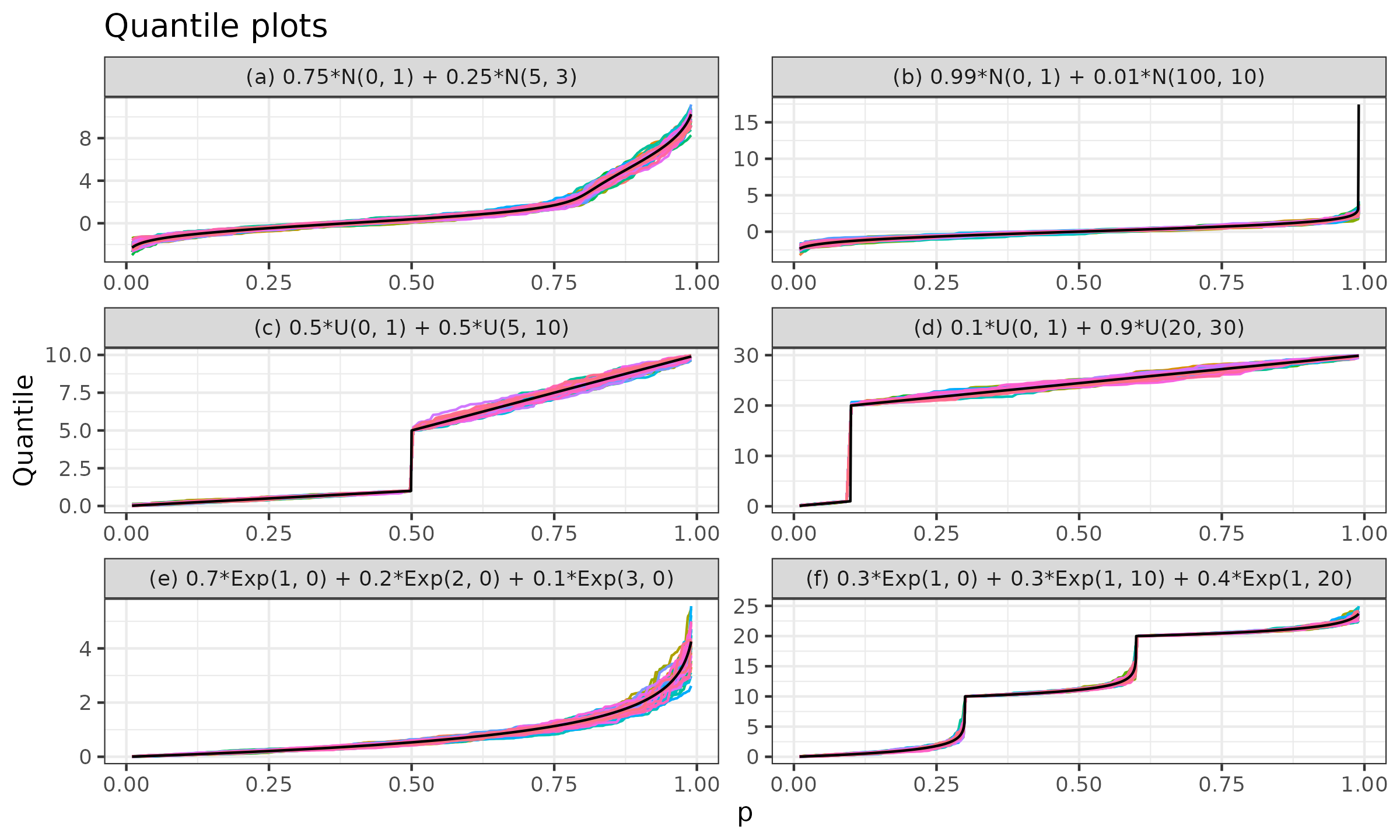
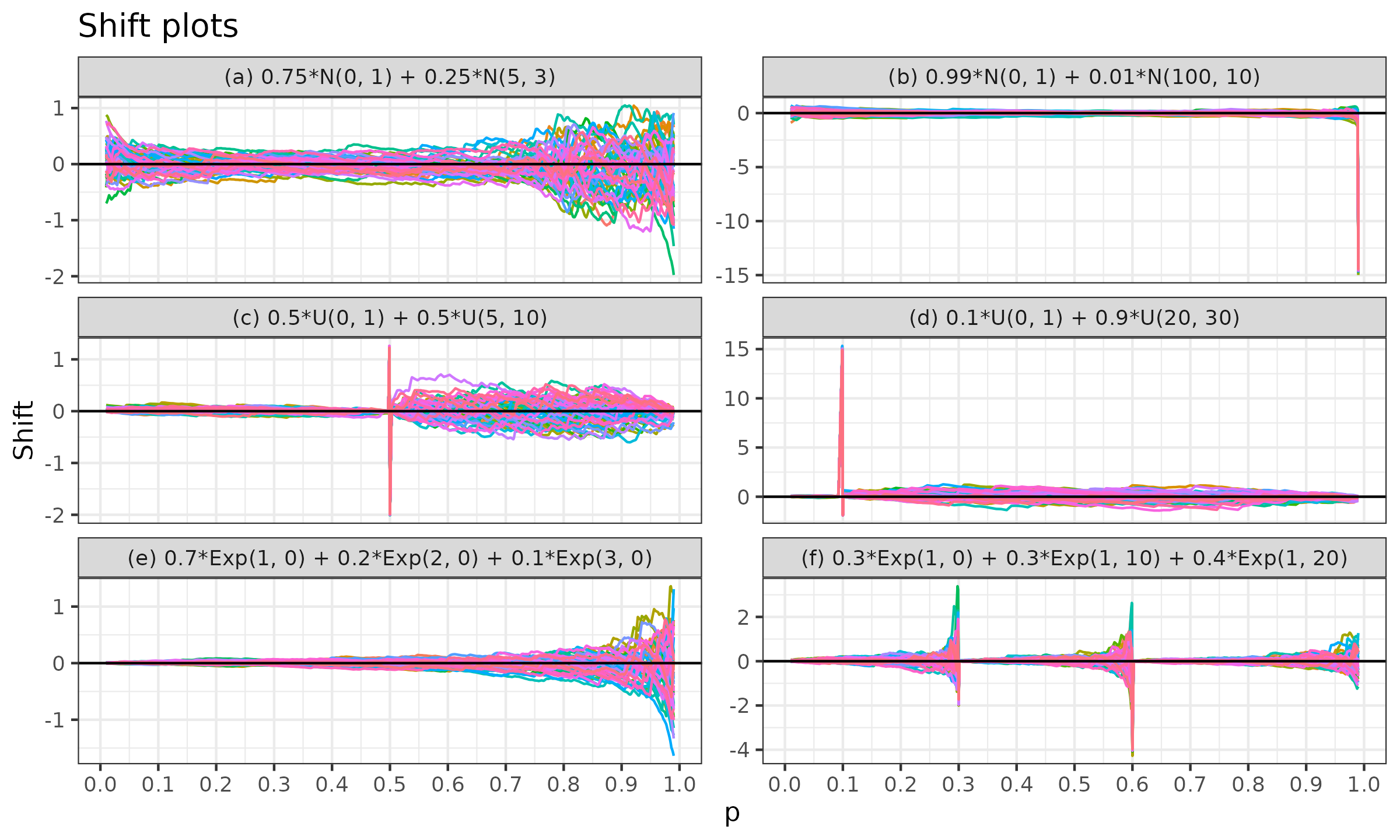
In this simulation, we consider the following six mixture distributions:
- (a) A mixture of two normal distributions with a small gap: $0.75 \cdot \mathcal{N}(0, 1) + 0.25 * \mathcal{N}(5, 3)$;
- (b) A mixture of two normal distributions with a large gap: $0.99 \cdot \mathcal{N}(0, 1) + 0.01 \cdot \mathcal{N}(100, 10)$;
- (c) A mixture of two uniform distributions with a small gap: $0.5 \cdot \mathcal{U}(0, 1) + 0.5 \cdot \mathcal{U}(5, 10)$;
- (d) A mixture of two uniform distributions with a large gap: $0.1 \cdot \mathcal{U}(0, 1) + 0.9 \cdot \mathcal{U}(20, 30)$;
- (e) A mixture of three exponential distributions: $0.7 \cdot \Exp(\lambda = 1) + 0.2 \cdot \Exp(\lambda = 2) + 0.1 \cdot \Exp(\lambda = 3)$;
- (f) A mixture of three shifted exponential distributions:
$0.3 \cdot \Exp(\lambda = 1,\, \textrm{shift} = 0) + 0.3 \cdot \Exp(\lambda = 1,\, \textrm{shift} = 10) + 0.4 \cdot \Exp(\lambda = 1,\, \textrm{shift} = 20)$.
For each mixture, we generate random samples of size $100$ from each individual distribution that contributes to the mixture. Next, we combine them into a weighted sample according to the individual distribution weights. For example, for the mixture (a), we get a sample of size $200$, in which $x_{\{1..100\}} \in \mathcal{N}(0, 1)$, $x_{\{101..200\}} \in \mathcal{N}(5, 3)$, $w_{\{1..100\}} = 0.75$, $w_{\{101..200\}} = 0.25$. Finally, we estimate the mixture quantiles using the weighted Hyndman–Fan Type 7 estimator for $p \in [0.01, 0.99]$ with step $\Delta p = 0.01$. We perform $50$ independent trials according to the described procedure. Thus, we get $50$ quantile function estimations per mixture.
In Figure ?, we can see the obtained quantile functions (the true quantiles are shown in black, the estimated quantiles are shown in color). As we can see, the estimations are quite accurate. There is some divergence from the true quantiles due to randomness and the small sample sizes, but the distribution form is still recognizable.
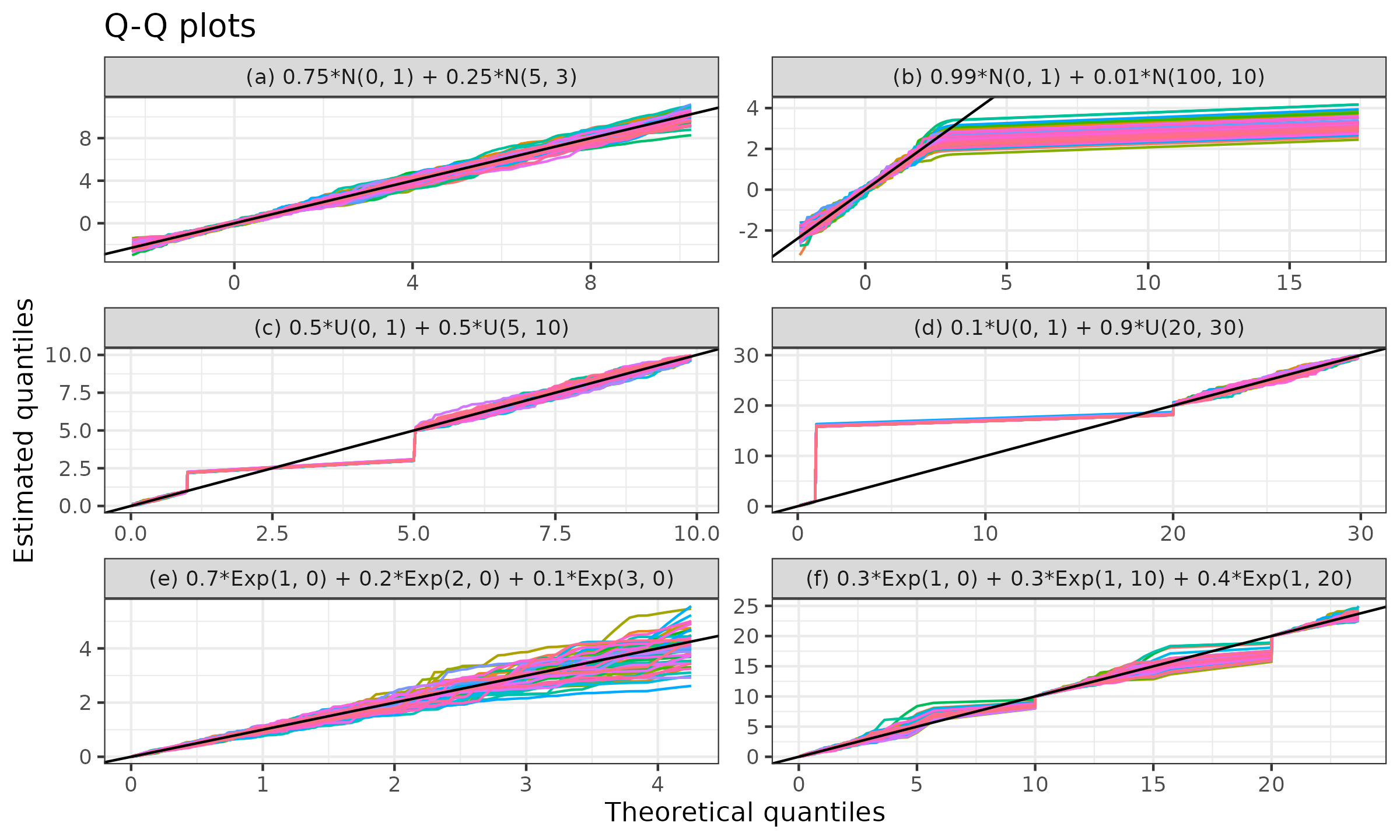
However, if we are interested not in the form of the whole distribution but rather in the values of individual quantiles, we should look at the Q-Q plot (see chambers1983) presented in Figure ? (the identity line is shown in black, the quantile lines are shown in color) and the Doksum’s shift plots (see doksum1974) presented in Figure ? (the zero shift is shown in black, the estimated quantile shifts are shown in color). As we can see, the quantile estimations near the low-density regions in the gaps between individual distributions are often not accurate: they significantly diverge from the true quantile values. It is a common issue not only for weighted quantile estimators but for any kind of quantile estimators. If we are aware of the fact that the target quantile is near a low-density region (e.g., it falls within a gap between individual distributions), we should probably use another estimating procedure and take the huge dispersion of estimations into account.
In this particular simulation, we have used large sample sizes, but the suggested weighted quantile estimator can be applied to samples of any size, including $n=1$ (unlike the straightforward method described in Section Preliminaries).
Summary
In this paper, we have discussed an approach for building weighted versions of existing quantile estimators. In particular, we have considered the traditional Hyndman–Fan Types 4–7 quantile estimators (extremely robust, not so efficient), the Harrell–Davis quantile estimator (efficient but not robust), and the trimmed Harrell–Davis quantile estimator (allows customizing trade-off between robustness and efficiency). However, the proposed scheme is generic and can be applied to other quantile estimators based on a linear combination of order statistics.
The suggested approach has several useful properties: it is a consistent extension of the existing quantile estimators (Requirement R1), sample elements with zero weights have no impact on the estimation (Requirement R2), small changes in weight coefficients produce small changes in the estimation (Requirement R3). These properties make the proposed estimators particularly beneficial for quantile exponential smoothing, but they can also be applied to other problems, such as estimating quantiles of a mixture distribution based on individual samples.
The obtained weighted quantile estimations can be used as a base for other estimators, such as various location estimators (e.g., Tukey’s trimean tukey1977, Midsummary tukey1977, Midhinge tukey1977, Gastwirth’s location estimator gastwirth1966) and scale estimators (e.g., interquartile and interdecile ranges, median absolute deviation hampel1974 rousseeuw1993 akinshin2022madfactors, quantile absolute deviation akinshin2022qad). The exponential smoothing can be easily applied to any of the derived estimators.
Reference implementation
The following is an R implementation of all the proposed weighted quantile estimators:
# Kish's effective sample size
kish_ess <- function(w) sum(w)^2 / sum(w^2)
# Weighted generic quantile estimator
wquantile_generic <- function(x, w, probs, cdf) {
n <- length(x)
if (is.null(w)) {
w <- rep(1 / n, n)
}
if (any(is.na(x))) {
w <- w[!is.na(x)]
x <- x[!is.na(x)]
}
nw <- kish_ess(w)
indexes <- order(x)
x <- x[indexes]
w <- w[indexes]
w <- w / sum(w)
t <- cumsum(c(0, w))
sapply(probs, function(p) {
cdf_values <- cdf(nw, p, t)
W <- tail(cdf_values, -1) - head(cdf_values, -1)
sum(W * x)
})
}
# Weighted Harrell-Davis quantile estimator
whdquantile <- function(x, w, probs) {
cdf <- function(n, p, t) {
if (p == 0 || p == 1)
return(rep(NA, length(t)))
pbeta(t, (n + 1) * p, (n + 1) * (1 - p))
}
wquantile_generic(x, w, probs, cdf)
}
# Weighted trimmed Harrell-Davis quantile estimator
wthdquantile <- function(x, w, probs, width = 1 / sqrt(kish_ess(w)))
sapply(probs, function(p) {
getBetaHdi <- function(a, b, width) {
eps <- 1e-9
if (a < 1 + eps & b < 1 + eps) # Degenerate case
return(c(NA, NA))
if (a < 1 + eps & b > 1) # Left border case
return(c(0, width))
if (a > 1 & b < 1 + eps) # Right border case
return(c(1 - width, 1))
if (width > 1 - eps)
return(c(0, 1))
# Middle case
mode <- (a - 1) / (a + b - 2)
pdf <- function(x) dbeta(x, a, b)
l <- uniroot(
f = function(x) pdf(x) - pdf(x + width),
lower = max(0, mode - width),
upper = min(mode, 1 - width),
tol = 1e-9
)$root
r <- l + width
return(c(l, r))
}
nw <- kish_ess(w)
a <- (nw + 1) * p
b <- (nw + 1) * (1 - p)
hdi <- getBetaHdi(a, b, width)
hdiCdf <- pbeta(hdi, a, b)
cdf <- function(n, p, t) {
if (p == 0 || p == 1)
return(rep(NA, length(t)))
t[t <= hdi[1]] <- hdi[1]
t[t >= hdi[2]] <- hdi[2]
(pbeta(t, a, b) - hdiCdf[1]) / (hdiCdf[2] - hdiCdf[1])
}
wquantile_generic(x, w, p, cdf)
})
# Weighted traditional quantile estimator
wquantile <- function(x, w, probs, type = 7) {
if (!(type %in% 4:9)) {
stop(paste("Unsupported type:", type))
}
cdf <- function(n, p, t) {
h <- switch(type - 3,
n * p, # Type 4
n * p + 0.5, # Type 5
(n + 1) * p, # Type 6
(n - 1) * p + 1, # Type 7
(n + 1 / 3) * p + 1 / 3, # Type 8
(n + 1 / 4) * p + 3 / 8 # Type 9
)
h <- max(min(h, n), 1)
pmax(0, pmin(1, t * n - h + 1))
}
wquantile_generic(x, w, probs, cdf)
}
Acknowledgments
The author thanks Ivan Pashchenko for valuable discussions; Ben Jann for the advice to use Kish’s effective sample size; Cay Oest for typo corrections.